压缩列表�实现原理
介绍
压缩列表是 Redis 中一种重要的数据结构,它具有内存紧凑、节省空间的特点。压缩列表是由连续内存块组成的顺序型数据结构,类似于数组,被设计为一种内存紧凑型的数据结构,旨在节省内存开销。它可以利用 CPU 缓存,并且会针对不同长度的数据进行相应编码。
缺陷:
- 不能保存过多元素,否则查询效率降低
- 新增或修改,占用内存空间重新分配,引发连锁更新问题
源码及原理
源码文件为:ziplist.c
数据结构
在ziplist的前面注释中描述:
*
* The general layout of the ziplist is as follows:
*
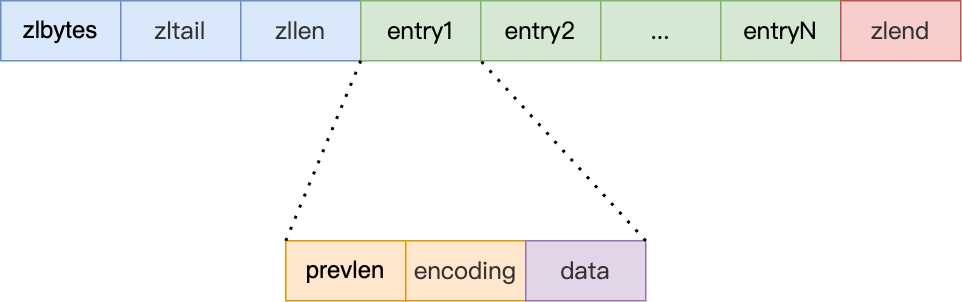
* <zlbytes> <zltail> <zllen> <entry> <entry> ... <entry> <zlend>

- zlbytes:记录整个压缩列表占用的内存字节数。
- zltail:记录压缩列表「尾部」节点距离起始地址的字节数,即列表尾的偏移量。
- zllen:记录压缩列表包含的节点数量。
- zlend:标记压缩列表的结束点,固定值为 0xFF(十进制 255)。
通过表头的这三个字段(zllen),可以直接定位到压缩列表的第一个元素和最后一个元素,其复杂度为 O (1)。然而,查找其他元素时,需要逐个查找,复杂度为 O (N),因此压缩列表不适合保存过多的元素。
对于每个节点:
/* We use this function to receive information about a ziplist entry.
* Note that this is not how the data is actually encoded, is just what we
* get filled by a function in order to operate more easily. */
/* 我们使用这个函数来接收有关ziplist条目的信息。
* 请注意,这不是数据的实际编码方式,只是我们通过一个函数填充的内容,以便更容易操作。 */
typedef struct zlentry {
unsigned int prevrawlensize; /* Bytes used to encode the previous entry len*/
/* 用于编码前一个条目长度的字节数 */
unsigned int prevrawlen; /* Previous entry len. */
/* 前一个条目的长度 */
unsigned int lensize; /* Bytes used to encode this entry type/len.
For example strings have a 1, 2 or 5 bytes
header. Integers always use a single byte.*/
/* 用于编码此条目类型/长度的字节数。
例如,字符串有1、2或5字节的头。整数总是使用一个字节。 */
unsigned int len; /* Bytes used to represent the actual entry.
For strings this is just the string length
while for integers it is 1, 2, 3, 4, 8 or
0 (for 4 bit immediate) depending on the
number range. */
/* 用于表示实际条目的字节数。
对于字符串,这只是字符串的长度,
而对于整数,它是1、2、3、4、8或0(对于4位立即数),
具体取决于数字范围。 */
unsigned int headersize; /* prevrawlensize + lensize. */
/* prevrawlensize + lensize。 */
unsigned char encoding; /* Set to ZIP_STR_* or ZIP_INT_* depending on
the entry encoding. However for 4 bits
immediate integers this can assume a range
of values and must be range-checked. */
/* 根据条目编码设置为ZIP_STR_*或ZIP_INT_*。
但是对于4位立即数,这可以假定为一系列值,
必须进行范围检查。 */
unsigned char *p; /* Pointer to the very start of the entry, that
is, this points to prev-entry-len field. */
/* 指向条目起始位置的指针,即指向前一个条目长度字段。 */
} zlentry;
压缩列表节点包含三部分内容:
- prevlen:记录了「前一个节点」的长度,目的是为了实现从后向前遍历。其空间大小跟前一个节点长度值有关,如果前一个节点的长度小于 254 字节,那么 prevlen 属性需要用 1 字节的空间来保存这个长度值;如果前一个节点的长度大于等于 254 字节,那么 prevlen 属性需要用 5 字节的空间来保存这个长度值。
- encoding:记录了当前节点实际数据的「类型和长度」,类型主要有两种:字符串和整数。如果当前节点的数据是整数,则 encoding 会使用 1 字节的空间进行编码,通过 encoding 确认了整数类型,就可以确认整数数据的实际大小。如果当前节点的数据是字符串,根据字符串的长度大小,encoding 会使用 1 字节 / 2 字节 / 5 字节的空间进行编码,encoding 编码的前两个 bit 表示数据的类型,后续的其他 bit 标识字符串数据的实际长度。
- data:记录了当前节点的实际数据,类型和长度都由 encoding 决定。
这种根据数据大小和类型进行不同的空间大小分配的设计思想,使得 Redis 能够有效地节省内存。
连锁更新问题
当压缩列表新增或修改某个元素时,如果空间不够,就需要重新分配内存空间。而当新插入的元素较大时,可能会导致后续元素的 prevlen 占用空间都发生变化,从而引起「连锁更新」问题。
例如,假设一个压缩列表中有多个连续的、长度在 250 - 253 之间的节点,因为这些节点��长度值小于 254 字节,所以 prevlen 属性需要用 1 字节的空间来保存这个长度值。此时,如果将一个长度大于等于 254 字节的新节点加入到压缩列表的表头节点,就会导致 e1 节点的 prevlen 属性需要从原来的 1 字节大小扩展为 5 字节大小。这种扩展会像多米诺骨牌效应一样,引发后续节点的 prevlen 属性也需要进行扩展,一直持续到结尾。
连锁更新一旦发生,会导致压缩列表占用的内存空间要多次重新分配,直接影响到压缩列表的访问性能。