响应式架构
代��码来源:https://github.com/sa-spring
WebMVC和WebFlux性能对比
现在我有两个简单的接口,一个是传统的mvc还有一个是flux,都是等待一段时间,打印信息
mvc如下:
@RestController
public class HelloController {
@GetMapping("/hello/{latency}")
public String hello(@PathVariable long latency) {
try {
TimeUnit.MILLISECONDS.sleep(latency); // 1
} catch (InterruptedException e) {
return "Error during thread sleep";
}
return "Welcome to reactive world ~";
}
}
flux如下:
@RestController
public class HelloController {
@GetMapping("/hello/{latency}")
public Mono<String> hello(@PathVariable int latency) {
return Mono.just("Welcome to reactive world ~").delayElement(Duration.ofMillis(latency)); // 1
}
}
还有一个scala的测试代码:
import io.gatling.core.Predef._
import io.gatling.http.Predef._
import scala.concurrent.duration._
class LoadSimulation extends Simulation {
// 从系统变量读取 baseUrl、path和模拟的用户数
val baseUrl = System.getProperty("base.url")
val testPath = System.getProperty("test.path")
val sim_users = System.getProperty("sim.users").toInt
val httpConf = http.baseUrl(baseUrl)
// 定义模拟的请求,重复30次
val helloRequest = repeat(30) {
// 自定义测试名称
exec(http("hello-with-latency")
// 执行get请求
.get(testPath))
// 模拟用户思考时间,随机1~2秒钟
.pause(1 second, 2 seconds)
}
// 定义模拟的场景
val scn = scenario("hello")
// 该场景执行上边定义的请求
.exec(helloRequest)
// 配置并发用户的数量在30秒内均匀提高至sim_users指定的数量
setUp(scn.inject(rampUsers(sim_users).during(10 seconds)).protocols(httpConf))
}
主要用来进行压力测试,其中flux端口为7001,mvc端口为7002
测试结果
在gatling中启动测试:
mvn gatling:test -Dgatling.simulationClass=LoadSimulation -Dbase.url=http://localhost:7002/ -Dtest.path=hello/1000 -Dsim.users=200
在测试期间,我们开启jconsole来进行观测
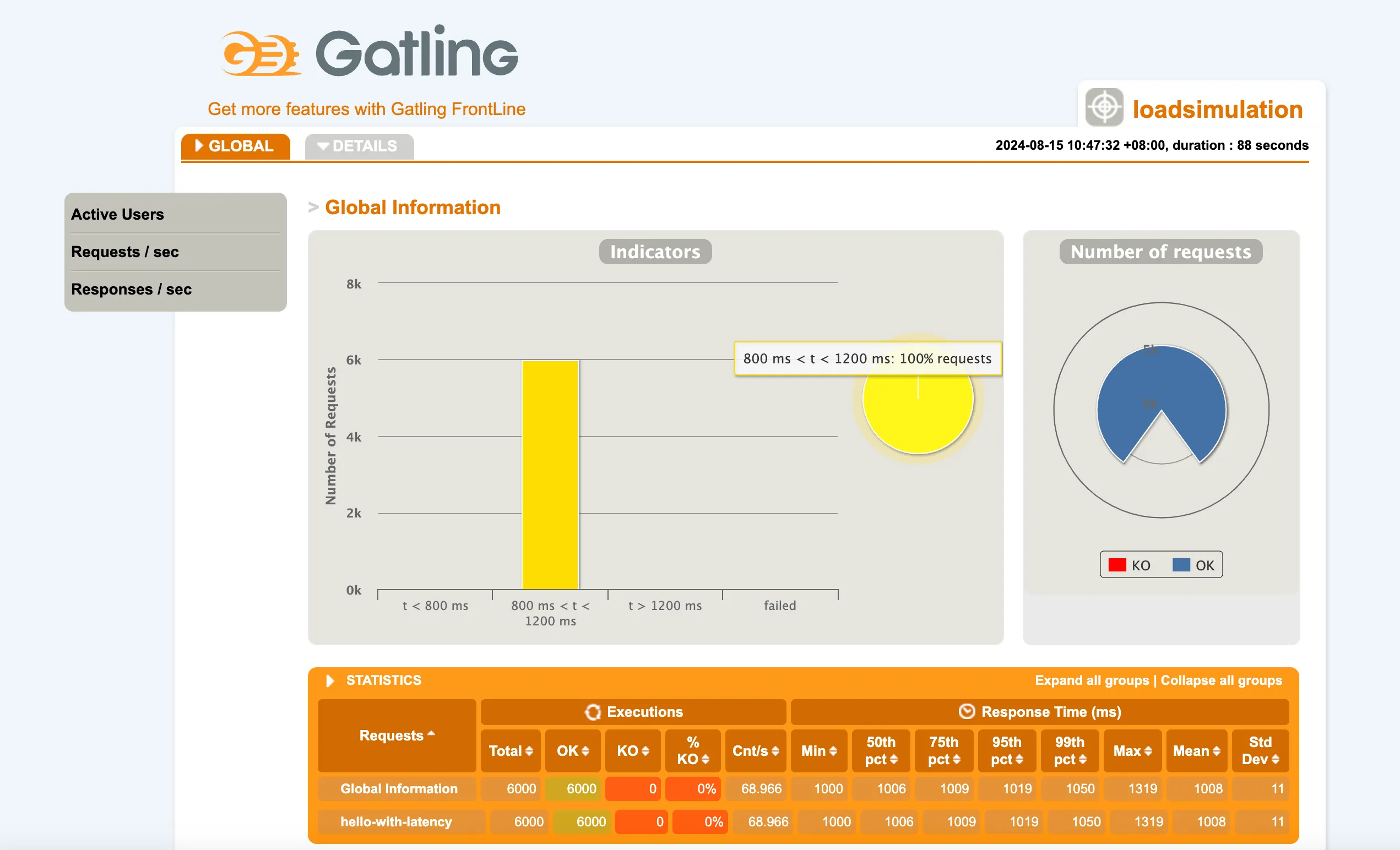
针对mvc得到的结果如下:

针对flux得到的结果如下:
在此期间的线程数对比:
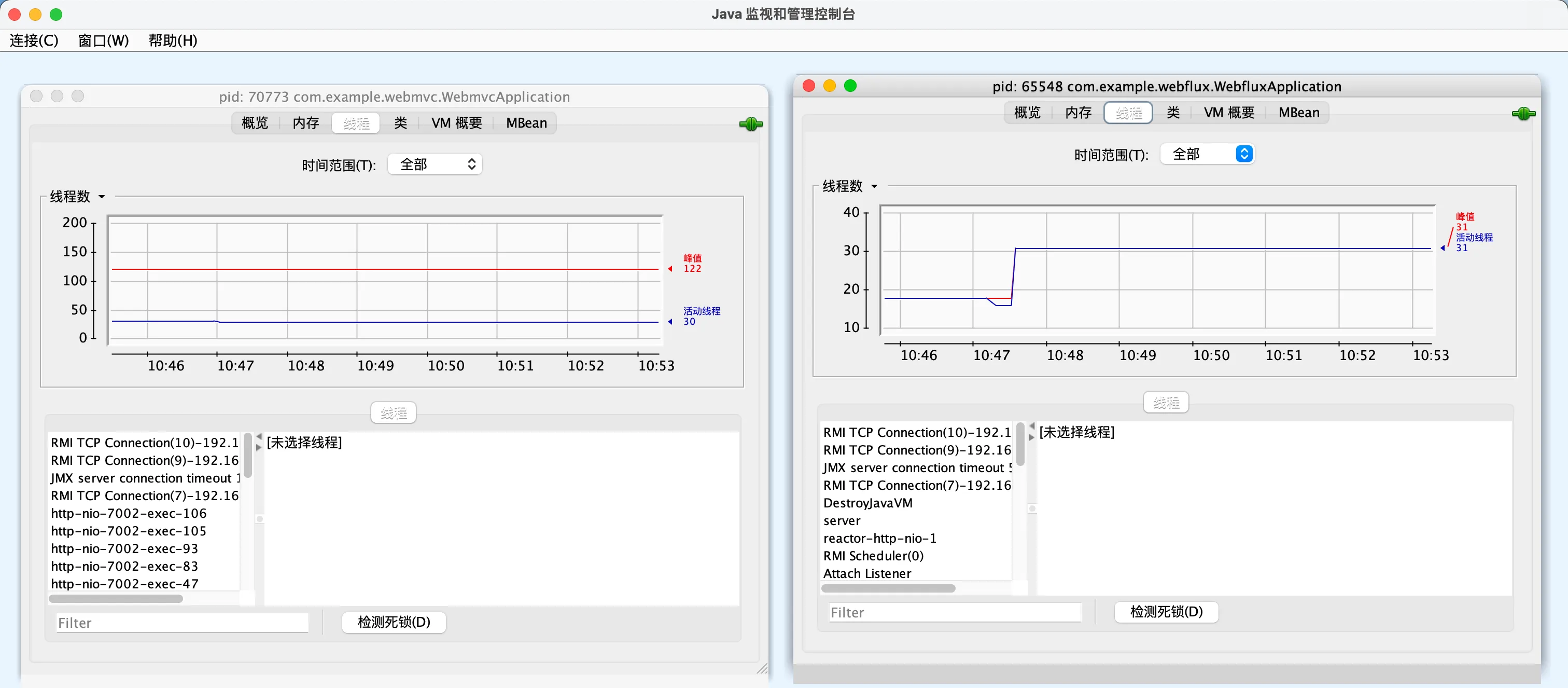
结果说明:在200个并发,接口sleep1s的情况下,mvc每秒处理67个请求,flux每秒处�理68个请求,平均等待时间mvc和flux都是1008ms,基本上没有什么区别,而线程数上,mvc会达到122个,而flux基本是只有31个
现在,我们把并发加到2000,重复10次,也就是20000个请求,
得到结果如下:
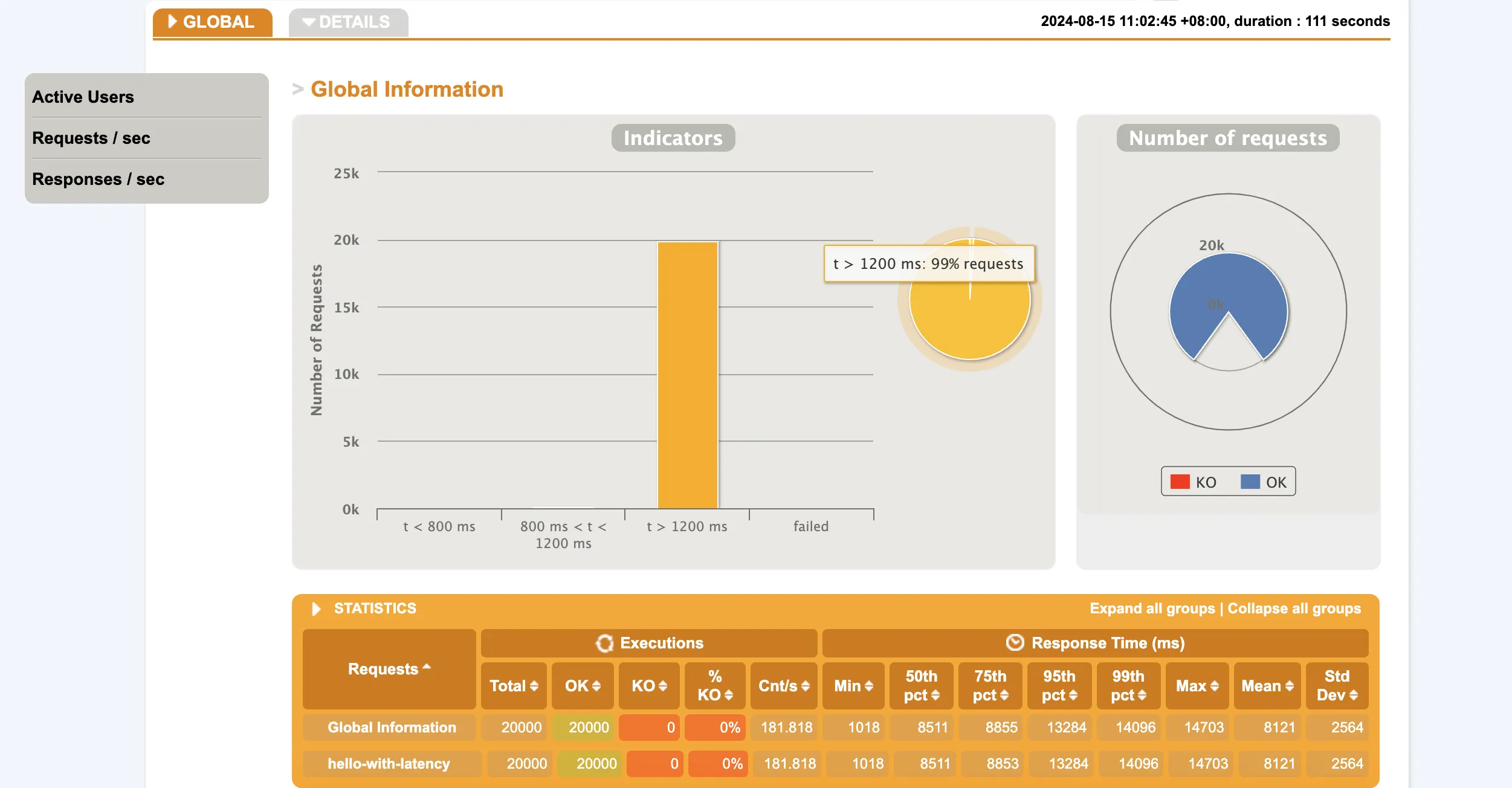
mvc:
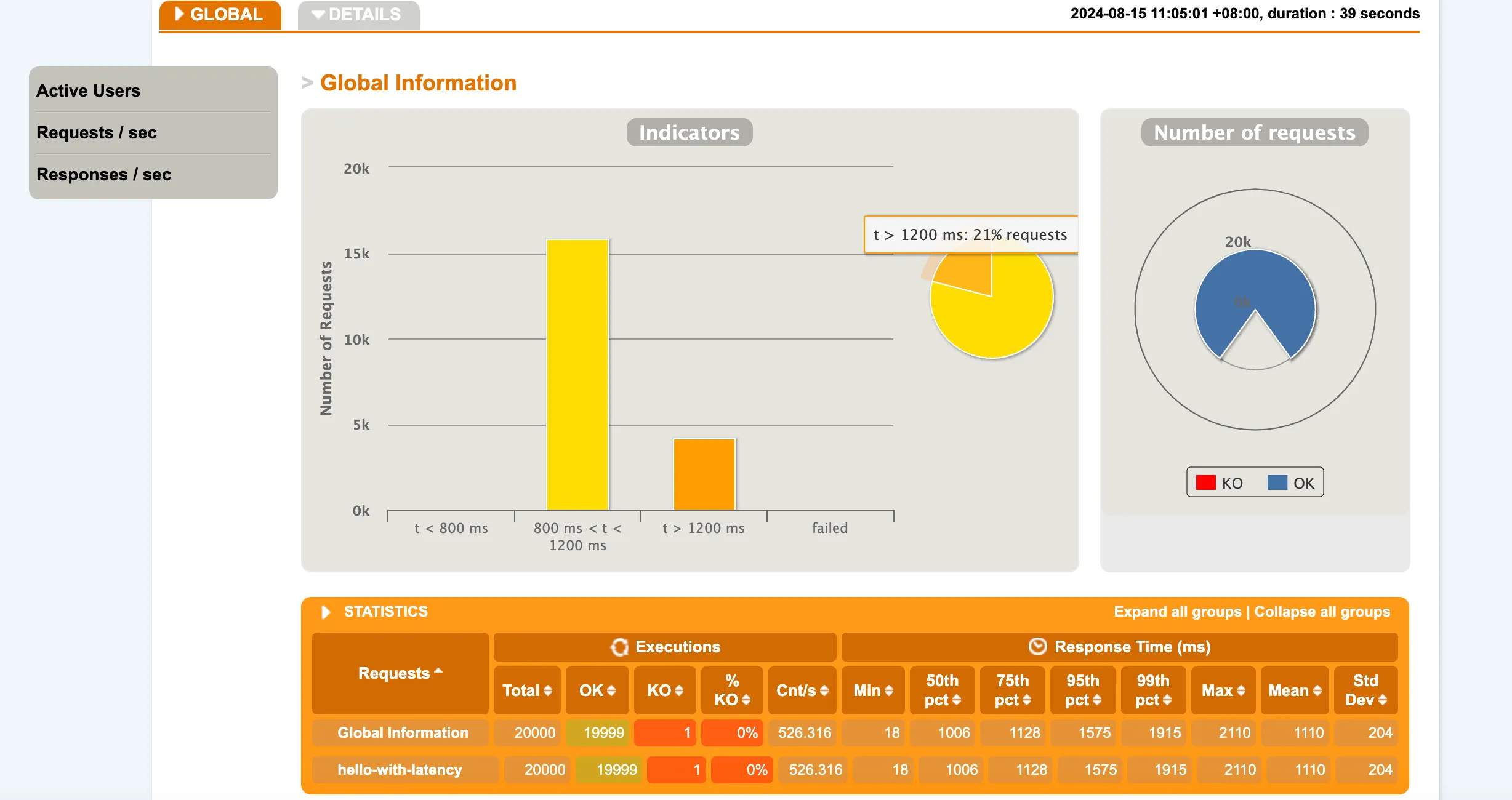
flux:
线程数对比:
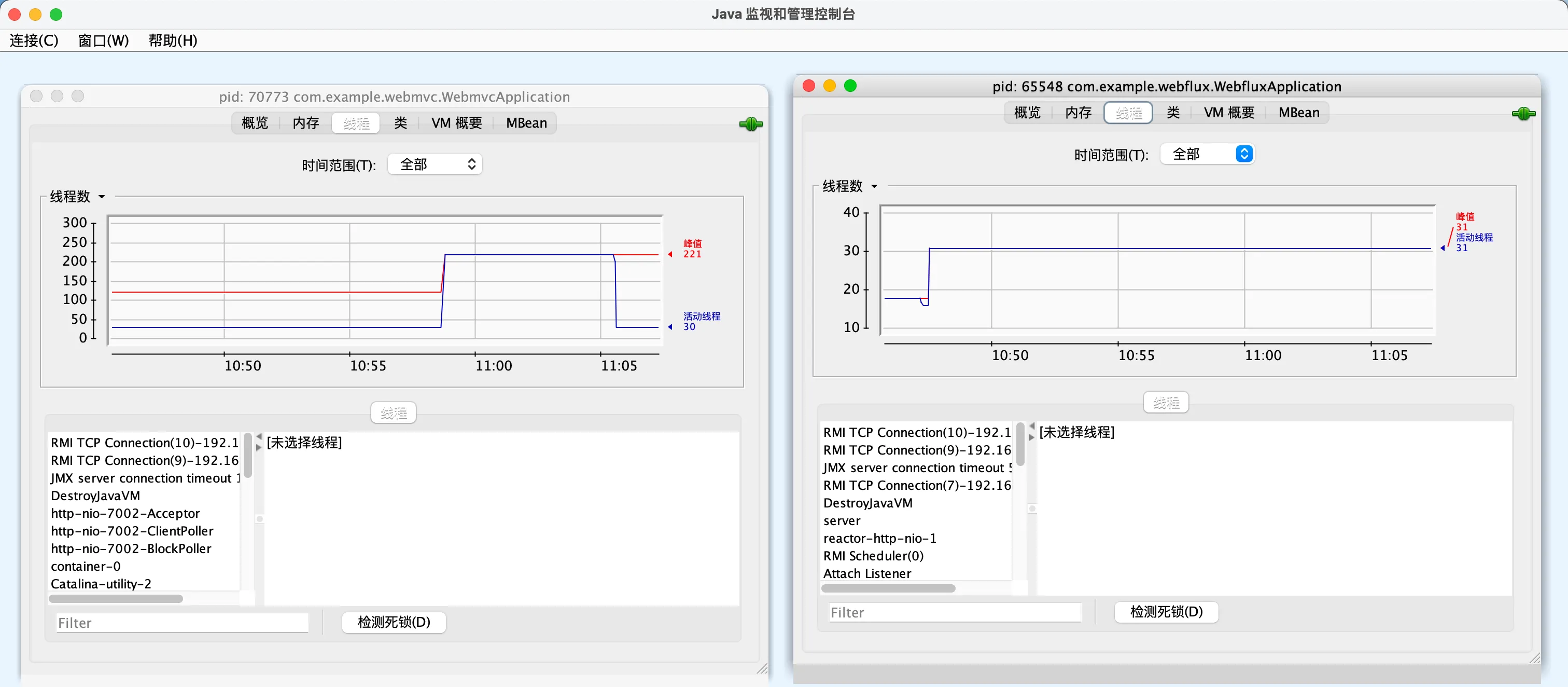
结果说明:mvc每秒处理181个请求,平均等待时间为8121ms,总共耗时111秒,flux每秒处理526个请求,平均等待时间1110ms,总共耗时39秒。线程数mvc达到了221,而flux依然为31
为什么会这样?
传统的MVC模式,每个线程到TimeUnit.MILLISECONDS.sleep(latency); // 1都会阻塞,tomcat服务器为了使得并发的用户都可以得到响应,所以会开启一个线程池,预先创建好大量线程,每个用户来了,就指定一个线程绑定,让这个线程去执行这个请求的代码。也就是需要去维护大量线程,但是线程创建多了会有很大的开销,
- 内存开销,一个线程1MB
- 线程调度开销:5000-10000clock cycles
如图:
所以我们在jconsole中也可以看到tomcat服务器的峰值时内存会大很多
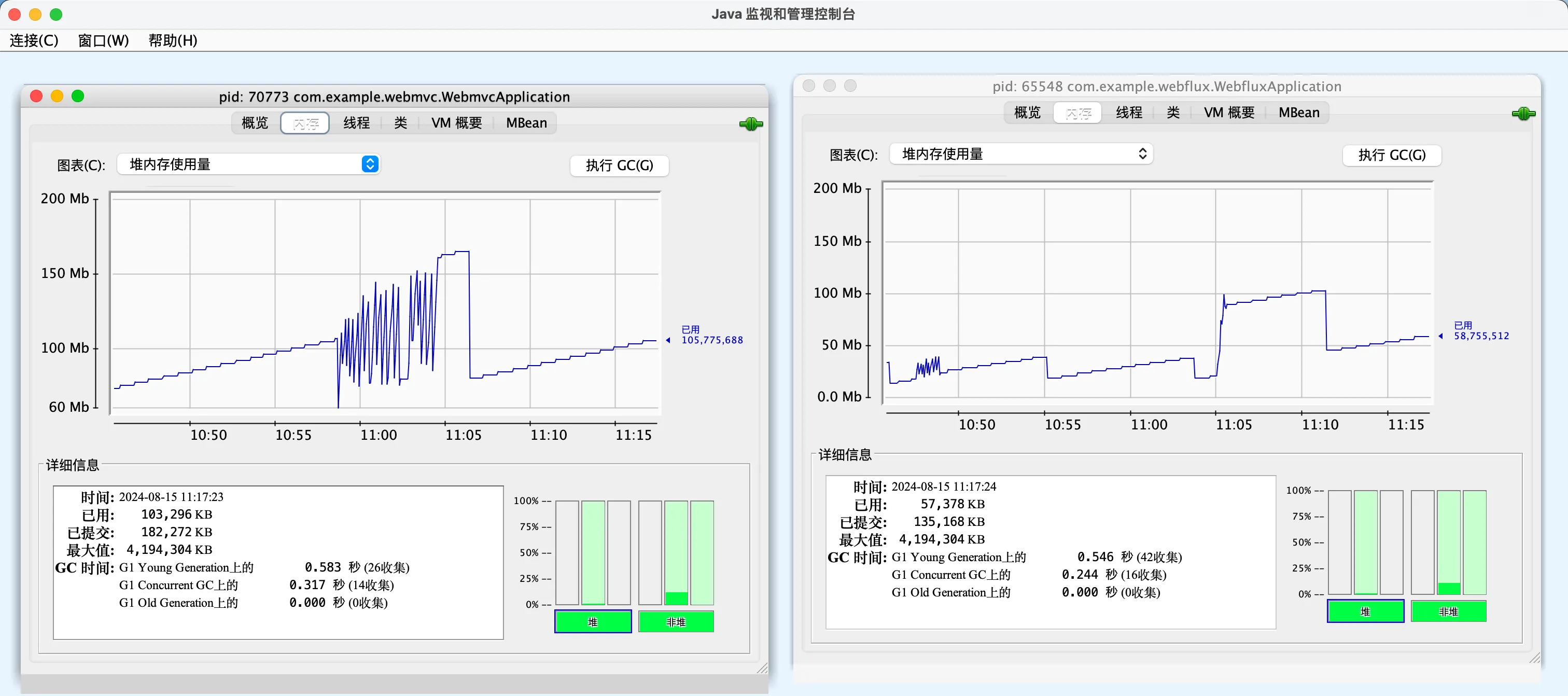
也就是mvc他的这个请求的服务量会少呢?为什么每个请求平均等待时间会长呢?因为这个系统在忙着分配线程,忙着在不断的调度线程,所以它很多的时间其实都花在创建线程,管理这个内存以及调度线程,进行这个线程上下文切换上面,所以他有大量的资源开销,在怎么去管理这么多现成的这个问题上面,所以这个每一个请求来了之后,有一个线程去对他服务,整个系统中间我有很多线程这样的一个方法,实现的并行化,其实效果并不好,效率很低的。
一个线程如果阻塞在哪里,这个线程相当于空闲了,他调度到CPU上,实际也不会做任何事情,所以一般我们出现了阻塞调用,不要让这个线程等着,而是使用callback这种回调函数,告诉系统,当你结束了,请你回调我的另一段代码,我就不等了,我去干别的事情了。这种基于回调函数的异步调用可以使得这个线程进入阻塞之后,还可以腾出手来做其他事情,当调用完了再使用回调函数通知你,把结果交给你。
在Java中,也就是可以使用future或者completableFuture,可以让你在未来某个时刻看结果好没好,这样就可以节省出时间来,让系统的利用率变高
例如:
CompletableFuture<List<String>> ids = ifhIds();
CompletableFuture<List<String>> result = ids.thenComposeAsync(l -> {
Stream<CompletableFuture<String>> zip =
l.stream().map(i -> {
CompletableFuture<String> nameTask = ifhName(i);
CompletableFuture<Integer> statTask = ifhStat(i);
return nameTask.thenCombineAsync(statTask, (name, stat) -> "Name " + name + " has stats " + stat);
});
List<CompletableFuture<String>> combinationList = zip.collect(Collectors.toList());
CompletableFuture<String>[] combinationArray = combinationList.toArray(new CompletableFuture[combinationList.size()]);
CompletableFuture<Void> allDone = CompletableFuture.allOf(combinationArray);
return allDone.thenApply(v -> combinationList.stream()
.map(CompletableFuture::join)
.collect(Collectors.toList()));
});
List<String> results = result.join();
这些代码实际上都在进行数据的加工和处理,但是这种组合式的处理,表达起来很难理解,于是有人提出了reactive思想。
计算机系统实际上就是在处理这些,不断发生的这些事件,所以我们可以把现实世界把它抽象出来,变成了一个事件的一个序列,变成了一个事件序列,我们的计算机系统是希望将这个事件序列的,进行不断的处理,那么换句话说,我们是等到这个事件发生的时候,当这个message或者这是event发生的时候,计算机系统去reactive去响应这些事件。
举个例子:银行里面处理这个用户的存款,那么只有当用户来存款的时候,提交一张存款的一张单子,这个时候我们的系统才会去处理这张单子是吧,那么处理这张单子过程,实际上就是用来去响应用户存款这样一个事件的这样一个过程
这种思想和异步调用不同,可以采用这种做叫做响应式的,编程模式去完成这样的一种设计,所以响应式的这种编程模式的意思就是说,我将这个系统所处理的对象,看成是一个事件的一个序列,所有东西所有的变化都看成是一串事件,那么系统做的事情,就是对这个事件进行一步一步的进行处理
Reactive Streams
上面这种思想对应的系统应该怎么设置呢?
对应系统中间就应该设计成一个所谓的,一个叫做reactive stream,一个响应式的一个流,所以流就是代表的一组事件的一个序列。流从哪里来:有一个叫做发布者产生了这些事件,形成一个stream,那么这些发布者的事件呢可以交给一组subscriber,一组订阅者进行处理。
这一点和事件驱动就很像了。有种设计模式叫发布订阅模式,但是发布订阅模式跟这有些区别。
在发布者和订阅者之间,有一个订阅的概念,订阅有两个方法,一个request,一个cancel。cancel是值订阅者不在订阅他了。并且,subscriber可以选择自己愿意从publisher哪里接收多少内容,这样订阅者对于发布者给他的东西是有些控制的,有点像计算机网络里的TCP的拥塞控制
不像发布订阅模式,publisher把事件发布出去,subscriber就会得到这个事件作出响应,没有对于publisher的一个控制
一方面我们可以控制他说我不要再订阅了,所以通过cancel方法可以来取消订阅,另一方面我还可以主动的告诉这个publisher,我在你那需要request多少个,而不是说你一味的发给我就行了。
并且:我们还可以在这个中间有一些processor,processor,就是将什么将一个publisher发布出来的,某一个类型的一个事件,把它可以转化成另外一个事件,交给subscriber进行处理啊,所以整个这个reactice stream,实际上就是定义了这样的一个系统的一种抽象,通过这样一种系统抽象,通过publisher去产生一些个事件,用subscriber去处理这些事件,然后呢subscriber通过subscription来对publisher的一个控制,中间可以有若干的processor来负责将这个数据进行,再进行一些转换。
Java9实现了这样一套想法:java.util.concurrent.Flow
public final class Flow {
private Flow() {}
@FunctionalInterface
public static interface Publisher<T> {
public void subscribe(Subscriber<? super T> subscriber);
}
public static interface Subscriber<T> {
public void onSubscribe(Subscription subscription);
public void onNext(T item);
public void onError(Throwable throwable);
public void onComplete();
}
public static interface Subscription {
public void request(long n);
public void cancel();
}
public static interface Processor<T,R> extends Subscriber<T>, Publisher<R> {}
}
代码实现:
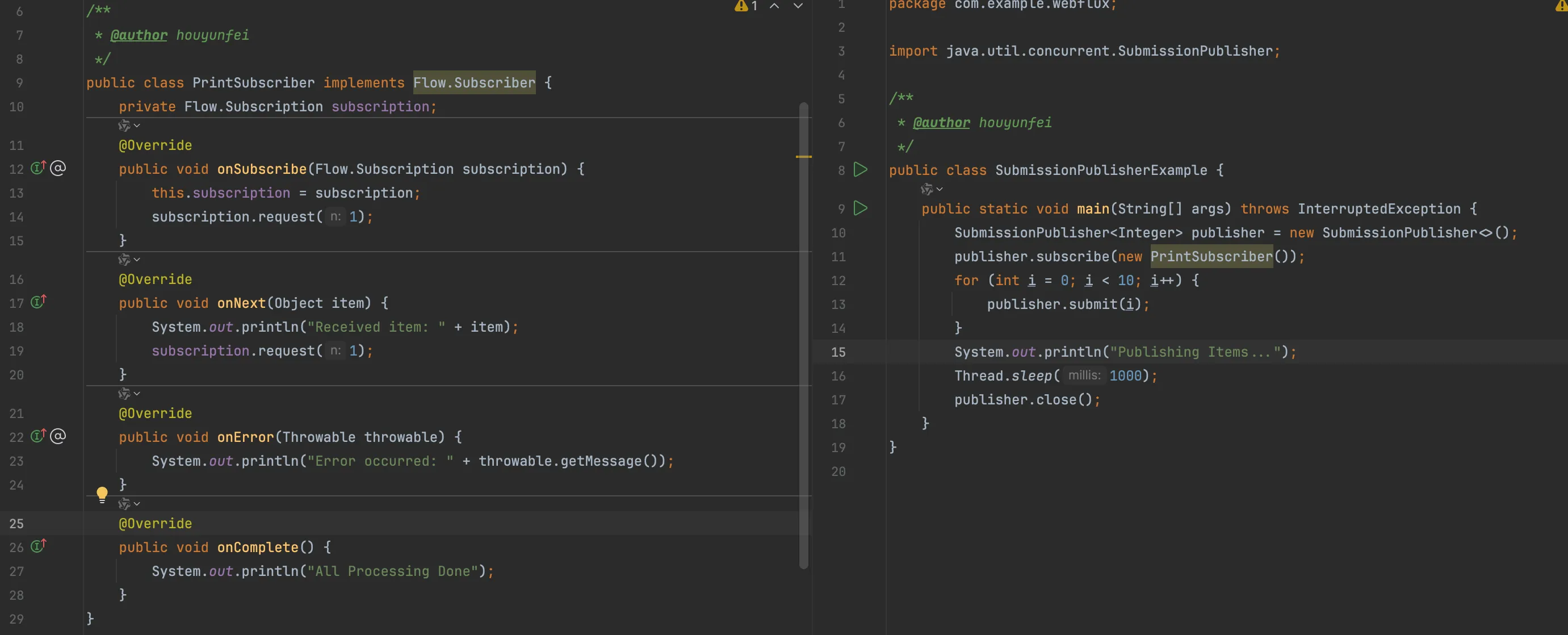
其中:subscription.request(1);就是用来控制速度的。订阅方对于发布方的数据产生速度的一个控制,使得这个订阅方呢不至于过载啊,不至于来不及处理你给我的数据,
仔细想想,也就是我的用户端他会给服务端一个背压,告诉服务端,你给我的压力太大了,我来不及接受,所以我也去给server一个反向的力,说我这边的压力很大。在这种角度下,其实用户端就是一个publisher,而服务端反而为subscribe。
在MVC机制中,缺少了这种总控制机制,server端只能忍受压力,用户不断的发送数据,请求。server端是没有办法操控client端的。
而我们的reactor响应式设计,非常强调这种供需平衡。如果有一个publisher,会产生一个一个的数据或者事件,是需要subscribe进行处理的,subscribe处理的能力本身是有限的,就像是我们这个server一样,它有一个线程池,它总是每次只有这么多线程是可以同时运行的,如果请求来的太多,那我就没办法的情况下,我可能可以增加一些的资源,比如说增加一些线程,但是不能无限制增加是吧,不能无限增加,等到某一个时刻,我你来的请求太多了,我增加的这些个啊资源也没办法满足了,怎么办呢,我就只好把你的请求把它给扔掉。
如何去解决这个问题呢?正确的做法不是一味的去增加处理方的资源,正确的做法应该是让供需双方能够相互调节嗯,处理方处理不过来了,应该告诉供需供求方啊,供给方说请你慢一点,说处理方如果现在发现资源很足,我还有很多空闲资源,那么应该告诉说你再给我多给一些资源啊
这种发布订阅模式是一种带被压控制的发布订阅模式,就不单单是说我的发布者将消息发出去,订阅者就直接消费这个消息,处理这个消息就结束了,而是说订阅者应该能够去通过某种机制呢,去产生一些反馈,告诉发布者什么时候应该发布多少给我啊,从而实现整个系统啊的性能和利用资源的利用率是达到一个最优的平衡
哪些框架实现了Reactive Streams:RxJava、Vert.X、akka、Spring Project Reactor
Project Reactor
在 Spring 相关的技术领域中,有一个名为 Project Reactor 的响应式流实现,它是由 Spring 的母公司 Pivotal 推出的项目。
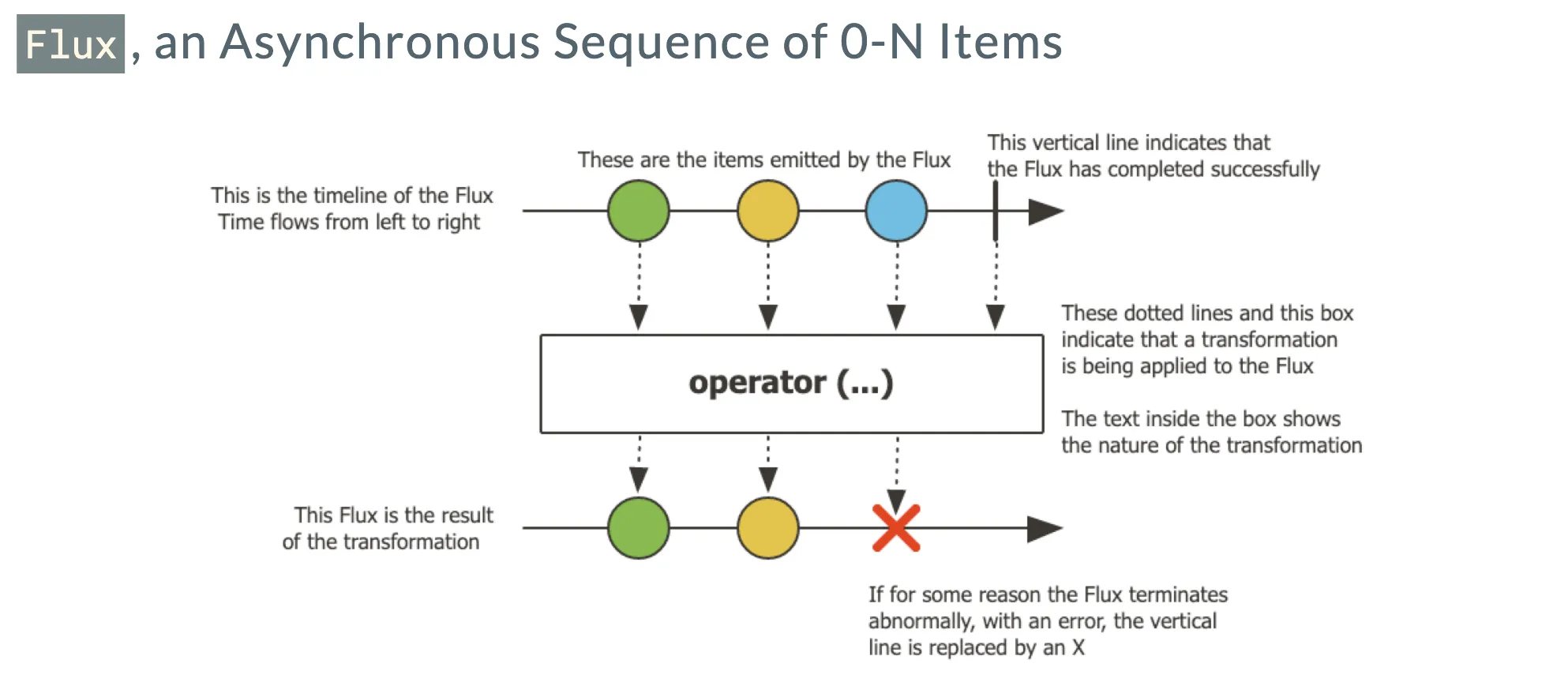
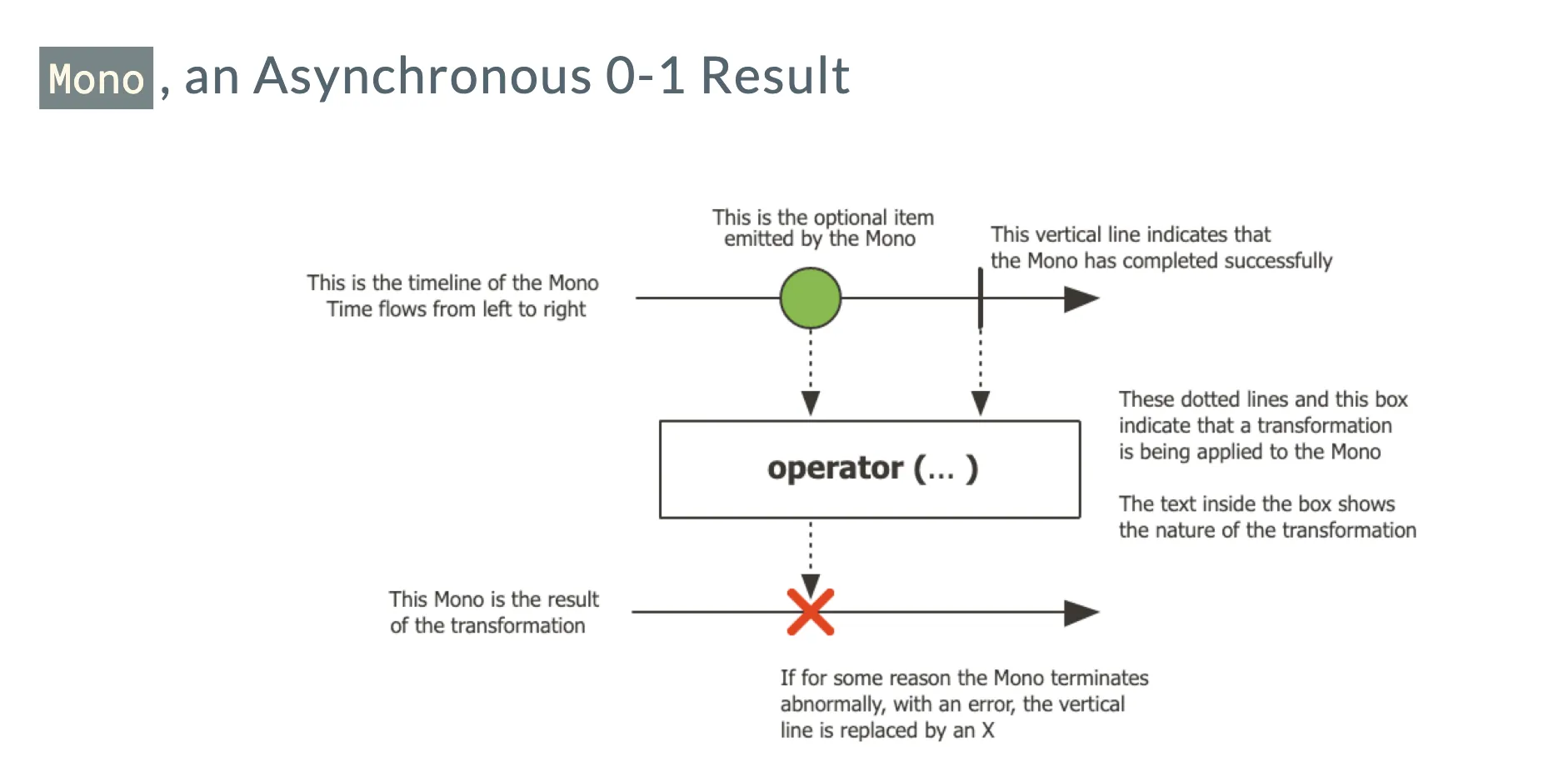
从概念上讲,当面对一串事件或数据时,我们可以运用响应式流的方式来处理。在 Project Reactor 中,对于 Publisher 有两个重要的定义,分别是 Flux 和 Mono。Flux 代表着一串数据或一系列元素,它能够产生数据对象,这些数据对象可以交由各种 Operator(处理器)进行处理,处理完成后还能转化为新的数据对象。而 Mono 是一种特殊的 Publisher,它可能包含零个或一个数据。这二者之所以分开设计,是因为 Mono 具有一些特定的方法。
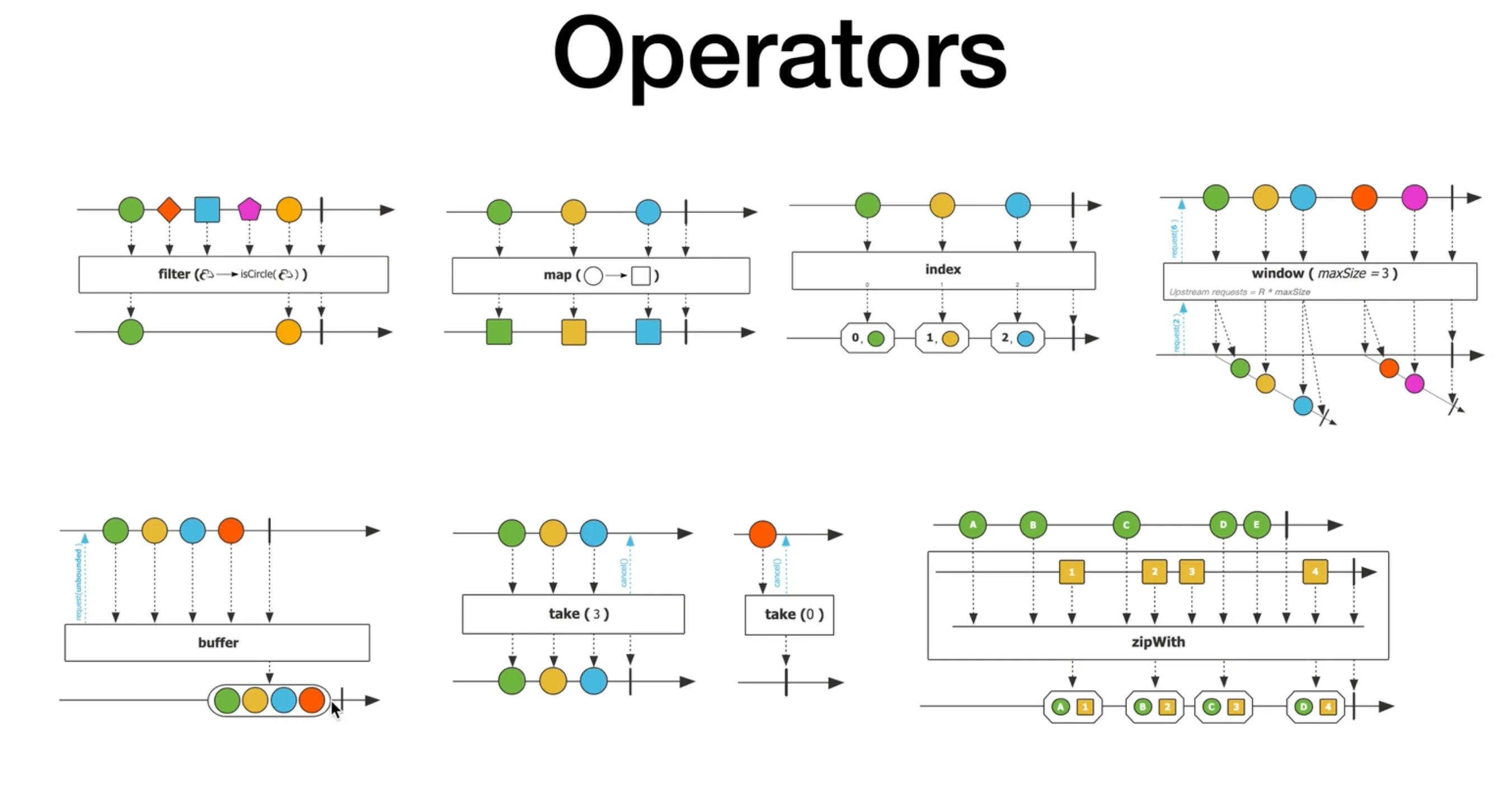
在 Project Reactor 项目中,Operator 十分丰富多样。例如,filter 可以按照特定逻辑对 Flux 中的数据流进行过滤;map 能够对数据进行映射转换;index 能为每个数据项添加编号;window 可以对数据流进行窗口划分;buffer 能对数据流中的数据进行缓冲处理;take 可以从流中只获取特定数量的数据;zip with 能够�将两个流组合在一起。通过这些 Operator 的处理,数据能够形成新的流,流中的每个数据项都是经过组合和处理的结果。
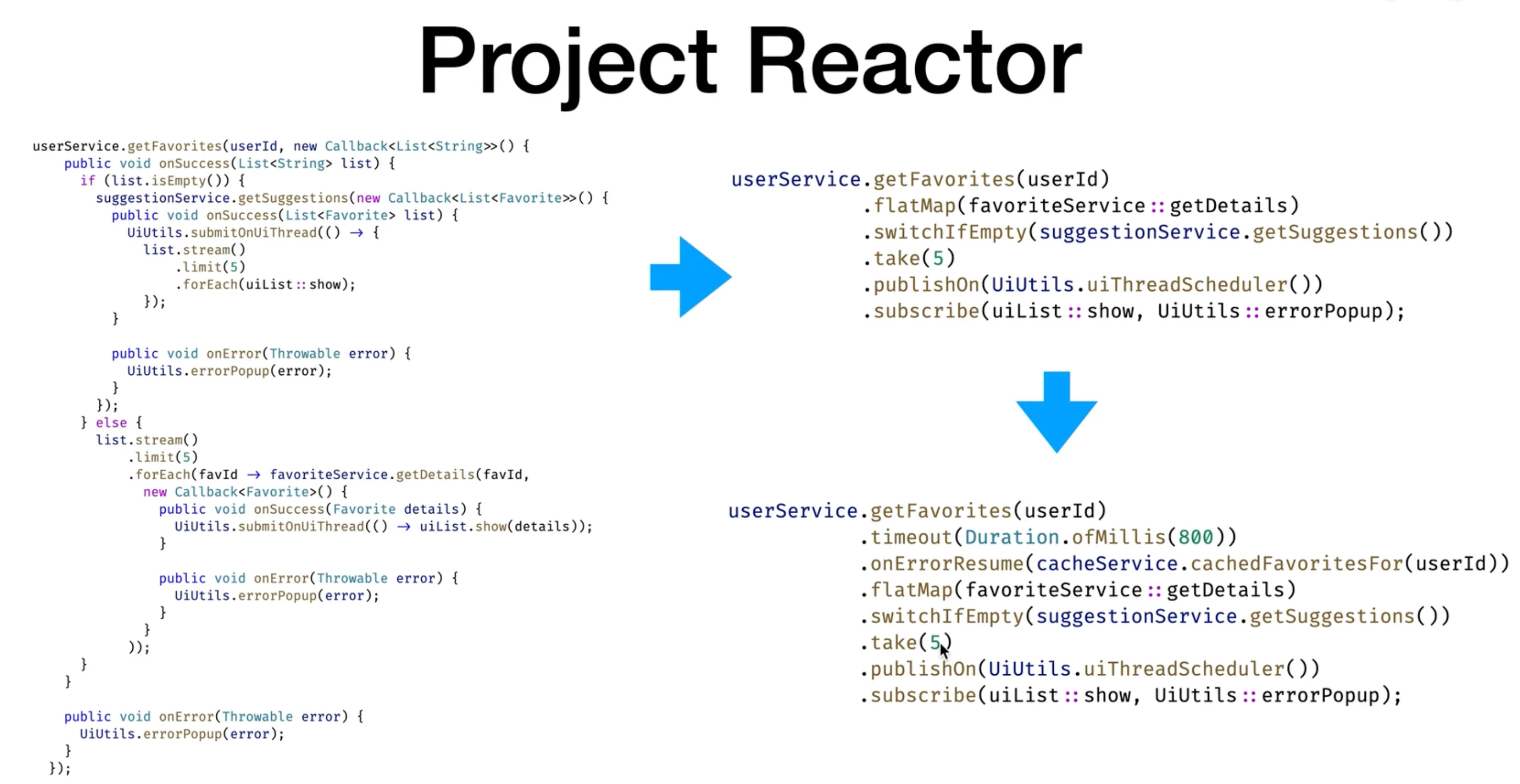
通过简单的例子可以更好地理解其应用。比如,使用 Reactor 模式表达根据用户 ID 获取其喜好的过程。首先获取喜好,然后进行处理,如果喜好为空则为用户列出建议,不为空则取出特定数量的喜好详情并交给 UI 显示。甚至还可以设置超时,比如规定获取喜好的方法最多 800ms 必须返回,否则报错。这些操作都可以理解为 Operator 的作用,从最初获取的数据形成数据流,经过一系列 Operator 的处理。
对比 Future 异步编程模式,Reactor 编程有着显著的不同。在使用 callback 方式设置的异步程序中,代码描述的是获取结果后的处理步骤。而在 Reactor 编程中,在 subscribe 之前,代码只是在描述应该做什么,而实际操作并未执行。只有当有人 subscribe 时,才会真正调用方法获取数据,并通过一系列 Operator 进行处理,最终交给相应线程处理。

命令式编程模式VS声明式编程模式:

这其实就是一种消息驱动的模式,通过这种声明式方式构建了消息处理流程。在这个过程中,处理可以是异步的,消息不是立即处理和返��回结果的,实现了时间上的解耦。如果 Operator 之间是跨主机的,还能在空间上解耦,整个消息处理流程不再局限于同一虚拟机或节点,可以跨越网络在其他节点进行下一步处理。
消息驱动和事件驱动的区别:本质上,它们在结构上没有区别,只是消息和事件的概念有所不同。事件在本地发生,通过消息可以传递到远程,让他人观察到事件的状态。
Project Reactor 为我们提供了强大而灵活的响应式编程方式,能够显著提升系统的性能和松耦合性。
Spring WebFlux
在实现了 Reactive Stream 之后,Spring 构建了一套全新的 Web 栈,即响应式栈(Reactive Stack)。以往我们所采用的传统 Web 栈,如 SOLID 栈,是基于用户发送请求后为每个请求分配一个线程进行服务的阻塞式调用过程。然而,若调用过程中存在长时间的计算任务、网络请求或线程操作,整个系统的吞吐效率将会受到显著影响。

有了响应式栈之后,情况发生了改变。对于用户发出的请求,Spring 将其视为一个事件来处理。通过 Web Flux 并借助 Reactor 的事件流方式进行处理后,再将结果返回给用户,而且返回的结果也可能是一个事件流。这意味着进入和流出的都是流,并且每个处理步骤都是异步的,从而在整个流的处理过程中始终保持非阻塞式的异步处理,大幅提高了整个系统的吞吐率。
我们通过一个员工管理工程的例子来深入理解。这是一个标准的 Spring Boot 应用,在 pom 文件中使用�的是 webflux 而非 web。在控制层(Controller)中有 EmployeeController,它接收请求。例如,获取某个特定 ID 的员工时,背后会调用 EmployeeReporter,从静态的 Map 中获取数据并将其转换为 Mono(只有一个元素的数据流)。获取所有员工时,则将 Map 中的所有数据作为 Flux(连续的数据流)推送出去,并模拟 100ms 的延迟以模拟数据库操作,同时在数据每次返回时进行打印。
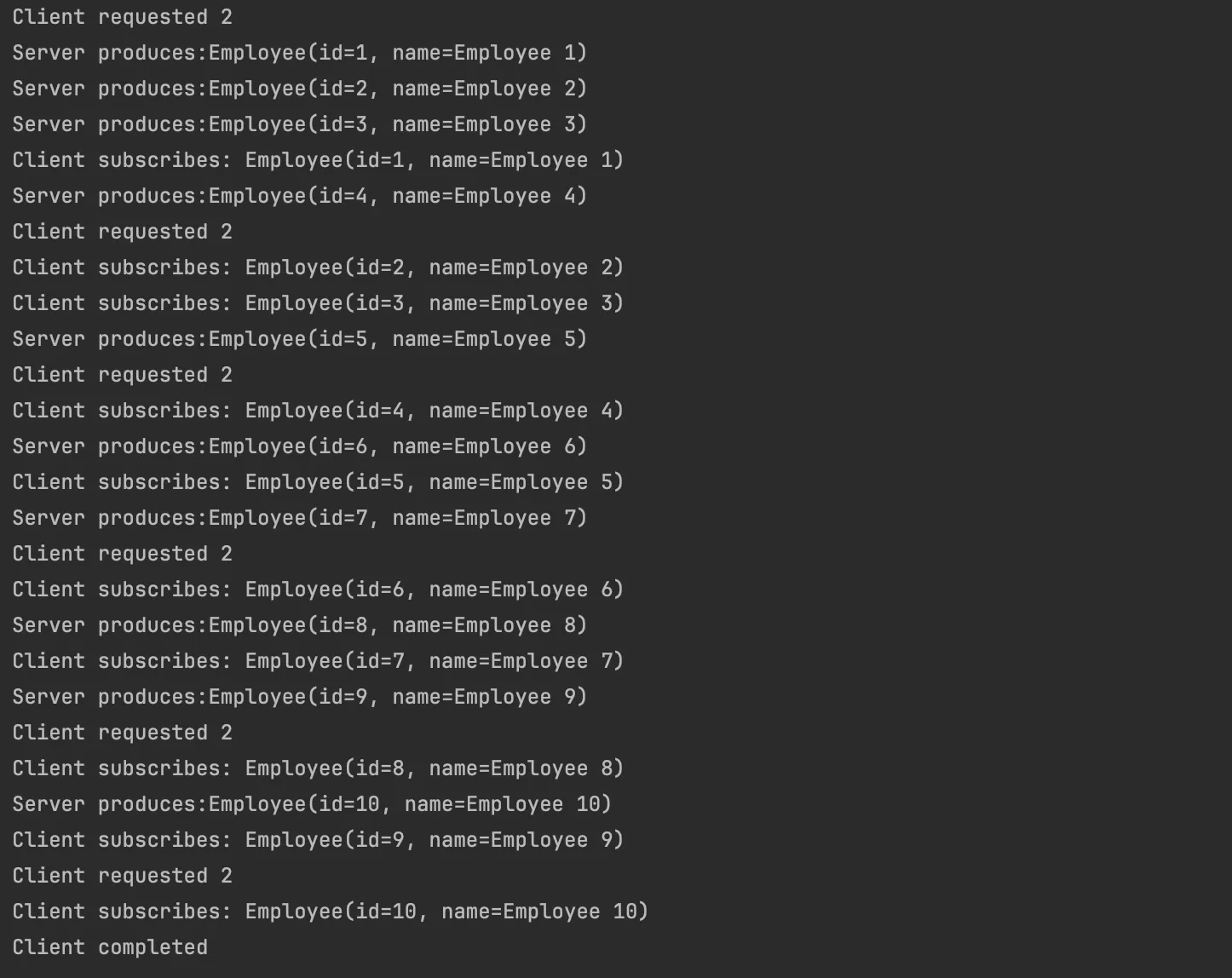
在客户端(Client)方面,使用了 Spring Web 中定义的 WebClient。在简单的版本中,让 Client 获取特定员工并打印结果。而在复杂一点的场景中,尝试获取若干员工时,引入了背压(Back Pressure)机制。在订阅时定制请求,每次只请求两个数据。通过这种方式,可以看到客户端和服务端之间的交互并非服务端直接返回所有结果,而是根据客户端的请求逐步放出数据。这体现了服务端是根据用户端的请求来产生数据并交付处理的。
整体的代码:
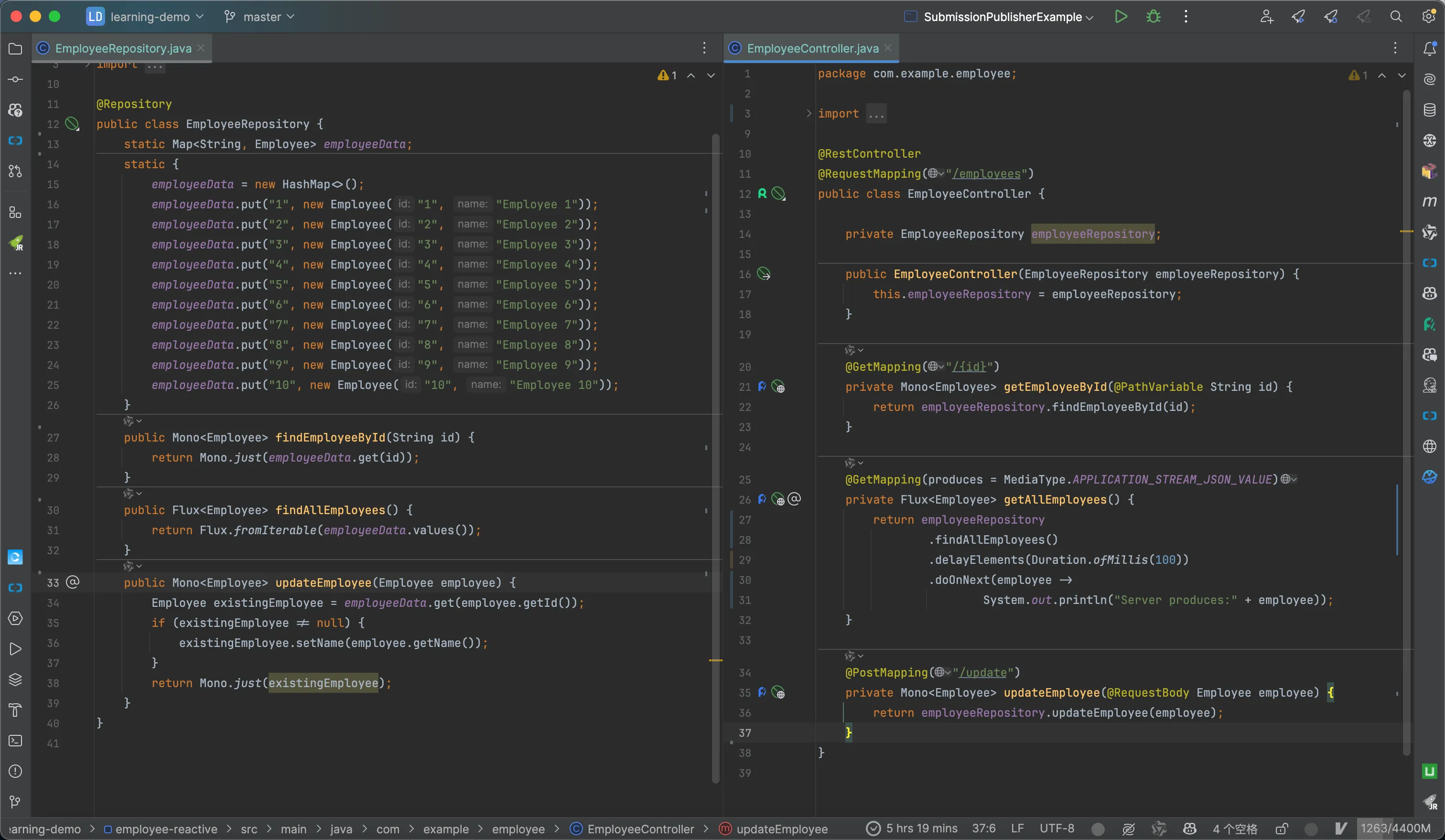
在调用方面,我们采用WebClient:
public class EmployeeWebClient {
WebClient client = WebClient.create("http://localhost:8080");
public void consume1() {
Mono<Employee> employeeMono = client.get().uri("/employees/{id}",
"1").retrieve().bodyToMono(Employee.class);
employeeMono.subscribe(System.out::println);
client.get().uri("/employees").retrieve().bodyToFlux(Employee.class).map(this::doSomeSlowWork)
.subscribe(employee -> {
System.out.println("Client subscribes: " + employee);
});
}
public void consume() {
client.get().uri("/employees").retrieve().bodyToFlux(Employee.class).map(this::doSomeSlowWork)
.subscribe(new Subscriber<Employee>() {
private Subscription subscription;
private Integer count = 0;
@Override
public void onNext(Employee t) {
count++;
if (count >= 2) {
count = 0;
subscription.request(2);
System.out.println("Client requested 2 ");
}
System.out.println("Client subscribes: " + t);
}
@Override
public void onSubscribe(Subscription subscription) {
this.subscription = subscription;
subscription.request(2);
System.out.println("Client requested 2 ");
}
@Override
public void onError(Throwable t) {
// TODO Auto-generated method stub
}
@Override
public void onComplete() {
System.out.println("Client completed");
}
});
}
private Employee doSomeSlowWork(Employee employee) {
try {
Thread.sleep(90);
} catch (InterruptedException e) {
}
return employee;
}
}
要实现这种高效的交互,有两个核心技术。其一,服务端的接口要生成一个流,当用户端和服务端之间标记为流时,会保持一个长连接。其二,用户端要使用 Spring Web 中定义的 WebClient,它能够按照响应式流的方式从服务端获取 Mono 或 Flux 的数据流,并通过订阅来支持,同时通过背压来协调。
运行结果:
在浏览器中直接调用,也不再是原本的fetch xhr了
当前的例子中尚未涉及服务端访问数据库的过程,因为传统数据库通常是同步阻塞式访问。不过,Spring 正在开发响应式的数据库连接,即 R2DBC 项目,旨在让传统关系数据库也能支持异步、非阻塞式的流处理过程。
在这个例子中,我们采用了响应式的 Web 栈,将用户请求和返回结果都视为数据流。通过背压机制,用户客户端和服务端能够实现有效的控制和沟通,避免因请求过多导致服务端阻塞或服务端返回数据过多导致客户端处理不及的情况,从而实现系统资源的高效利用。
Reactive System
在当今的数字化时代,计算机系统的数据处理需求发生了巨大的变化。曾经,系统运行在数十个机器上,响应时间较慢,允许定期的断线维护,数据量也相对较少。然而,如今像微信、Zoom 等应用规模庞大,并发用户众多,对系统的要求达到了前所未有的高度。
用户期望系统具备极高的响应速度,不允许出现明显的等待。同时,系统应具备强大的抗压和容错能力,避免频繁出错。此外,系统还需要具备弹性,能够根据用户规模和请求量灵活调整处理能力。更重要的是,系统应是消息驱动的,能够及时处理数据和事件。
具有这些特性的系统被称为响应式系统(Reactive System)。响应式系统在设计上应满足一系列要求,比如系统组件松耦合,具有高度的可扩展性,开发和维护简单,且能避免严重错误,保持高响应度,为用户提供良好的交互体验。
总结来看,响应式系统应具备弹性,能够水平扩展;具备容错性,错误能被隔离,避免系统大规模失效;采用消息驱动的异步处理方式,及时响应请求,确保系统的高响应度。
Reactive Stream 方式,实现了一种抽象的异步消息驱动机制,并通过背压在多个组件间协调处理流程,避免系统组件被压垮,使用户获得良好的响应体验。事件驱动架构、领域驱动架构、系统集成架构等,都是消息驱动的设计方法,采用异步消息驱动机制,结合水平扩展、云计算和微服务等相关技术,最终构建出具备良好响应性的响应式系统。
总结
反应式编程和反应式架构是近年来在软件开发领域中逐渐成为主流的一种编程和架构设计方法。它们在处理异步、并发和流式数据时具有显著优势,使得开发者能够更轻松地处理复杂的系统。
反应式编程是一种编程范式,它允许开发者以声明式方式编写代码,而不是以命令式方式编写代码:
- 事件:表示发生在系统中的一种变化,如用户输入、数据更新等。
- 观察者:监听事件并在事件发生时执行某些操作的对象。
- 发布-订阅模式:事件发布者发布事件,观察者订阅相关事件并执行相应的操作。
反应式架构是一种软件架构设计方法,它主要面向流式数据和异步操作
- 流:表示一种连续的数据流,如数据流式处理、事件流等。
- 处理器:对流数据进行处理的组件,如过滤、转换、聚合等。
- 连接器:连接处理器和流数据的组件,实现数据的传输和转发。