编辑距离算法匹配
在伙伴匹配系统中,算法的选择和优化对于准确找到合适的匹配伙伴至关重要。本文将详细介绍编辑距离算法在伙伴匹配中的应用,以及对该算法的优化和改进。
编辑距离算法匹配原理
编辑距离算法用于衡量两个字符串之间的相似度,其核心思想是计算将一个字符串转换为另一个字符串所需的最少操作次数(增、删、改字符)。在伙伴匹配中,我们可以将用户的标签看作字符串,通过计算编辑距离来确定用户之间的标签相似度。
随机匹配实现
根据标签tag进行匹配,找到具有相似标签的用户。具体步骤如下:
- 找到与当前用户具有共同标签最多的用户。
- 共同标签越多,分数越高,在匹配结果中越排在前面。
- 如果没有匹配的用户,则随机推荐几个。
public static int minDistance(List<String> tagList1, List<String> tagList2) {
int n = tagList1.size();
int m = tagList2.size();
if (n * m == 0)
return n + m;
int[][] d = new int[n + 1][m + 1];
for (int i = 0; i < n + 1; i++) {
d[i][0] = i;
}
for (int j = 0; j < m + 1; j++) {
d[0][j] = j;
}
for (int i = 1; i < n + 1; i++) {
for (int j = 1; j < m + 1; j++) {
int left = d[i - 1][j] + 1;
int down = d[i][j - 1] + 1;
int left_down = d[i - 1][j - 1];
if (!tagList1.get(i - 1).equals(tagList2.get(j - 1)))
left_down += 1;
d[i][j] = Math.min(left, Math.min(down, left_down));
}
}
return d[n][m];
}
public List<User> matchUsers(long num, User loginUser) {
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
queryWrapper.select("id", "tags");
queryWrapper.isNotNull("tags");
List<User> userList = this.list(queryWrapper);
String tags = loginUser.getTags();
Gson gson = new Gson();
List<String> tagList = gson.fromJson(tags, new TypeToken<List<String>>() {
}.getType());
List<Pair<User, Long>> list = new ArrayList<>();
for (int i = 0; i < userList.size(); i++) {
User user = userList.get(i);
String userTags = user.getTags();
//无标签或者是自己,跳过
if (StringUtils.isBlank(userTags) || user.getId().equals(loginUser.getId())) {
continue;
}
List<String> userTagList = gson.fromJson(userTags, new TypeToken<List<String>>() {
}.getType());
int distance = AlgorithmUtils.minDistance(tagList, userTagList);
list.add(new Pair<>(user, (long) distance));
}
//按照编辑距离从小到达排序
List<Pair<User, Long>> topUserPairList = list.stream()
.sorted((a, b) -> (int) (a.getValue() - b.getValue()))
.limit(num)
.collect(Collectors.toList());
List<Long> userIdList = topUserPairList.stream().map(userLongPair -> userLongPair.getKey().getId()).collect(Collectors.toList());
QueryWrapper<User> userQueryWrapper = new QueryWrapper<>();
userQueryWrapper.in("id", userIdList);
Map<Long, List<User>> userIdUserListMap = this.list(userQueryWrapper)
.stream()
.map(user -> getSafetyUser(user))
.collect(Collectors.groupingBy(User::getId));
List<User> finalUserList = new ArrayList<>();
for (Long userId : userIdList) {
finalUserList.add(userIdUserListMap.get(userId).get(0));
}
return finalUserList;
}
编辑距离算法的详细介绍可参考https://blog.csdn.net/DBC_121/article/details/104198838,其核心是计算字符串 1 通过最少多少次增删改字符的操作可以变成字符串 2。
对所有用户匹配并取 TOP 的优化
在对所有用户进行匹配并取 TOP N 的过程中,直接取出所有用户,依次和当前用户计算分数,然后取前 N 名的方法存在一些性能问题。例如,在数据量大时,这种方式可能会导致较长的计算时间和较高的内存占用。
- 避免在数据量大时循环输出日志:取消掉不必要的日志输出可以显著减少计算时间。例如,在之前的测试中,取消掉日志后计算时间从 54 秒减少到 20 秒。
- 优化内存占用:原来的方法中,使用
Map存储所有的分数信息,会占用大量内存。为了解决这个问题,可以维护一个固定长度的有序集合(如sortedSet),只保留分数最高的几个用户,以时间换空间。例如,对于一个取 TOP 5 的场景,当已有用户的分数超过当前最低分数时,就可以将新用户加入集合,并剔除分数最低的用户。 - 细节处理:在匹配过程中,需要剔除自己,以避免出现无意义的匹配。
- 查询优化:
- 过滤掉标签为空的用户:减少不必要的计算。
- 根据部分标签取用户:如果能区分出哪个标签比较重要,可以根据这些重要��标签进行查询,提高查询效率。
- 只查需要的数据:例如,在上述代码中,只查询用户的
id和tags,减少了数据的传输和处理量,将计算时间从原来的 20 秒进一步减少到 7.0 秒。
- 提前处理:
- 提前缓存用户数据:对于一些不经常更新的数据,可以提前将所有用户缓存起来,避免在匹配时频繁查询数据库。
- 提前运算结果并缓存:针对一些重点用户,可以提前运算出匹配结果并进行缓存,以提高实时匹配的速度。
在大数据推荐场景中,面对海量的数据(如几亿个商品),如果对所有数据进行计算和查询,显然是不可行的。通常需要采用类似检索、召回、粗排、精排、重排序等步骤来优化推荐过程。
- 检索:尽可能多地查符合要求的数据,比如按记录查。
- 召回:查询可能要用到的数据,但不进行复杂的运算。
- 粗排:进行粗略排序,使用相对轻量的运算。
- 精排:进行精细排序,确定固定排位。
通过这些优化步骤,可以提高系统的性能和响应速度,为用户提供更好的体验
编辑距离算法优化
使用编辑距离算法实现了根据标签匹配最相似用户的功能,并通过优先队列来优化 TOP N 运算过程中的内存占用。
原来是先一次性把数据全部都查出来,然后再进行排序,取出前 N 名。这种方式的代码如下:
private List<User> matchUsersByListSorted(long num, User loginUser) {
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
queryWrapper.select("id", "tags");
queryWrapper.isNotNull("tags");
List<User> userList = this.list(queryWrapper);
String tags = loginUser.getTags();
Gson gson = new Gson();
List<String> tagList = gson.fromJson(tags, new TypeToken<List<String>>() {
}.getType());
List<Pair<User, Long>> list = new ArrayList<>();
for (int i = 0; i < userList.size(); i++) {
User user = userList.get(i);
String userTags = user.getTags();
//无标签或者是自己,跳过
if (StringUtils.isBlank(userTags) || user.getId().equals(loginUser.getId())) {
continue;
}
List<String> userTagList = gson.fromJson(userTags, new TypeToken<List<String>>() {
}.getType());
int distance = AlgorithmUtils.minDistance(tagList, userTagList);
list.add(new Pair<>(user, (long) distance));
}
//按照编辑距离从小到达排序 编辑距离越小说明相似度越高
List<Pair<User, Long>> topUserPairList = list.stream()
.sorted((a, b) -> (int) (a.getValue() - b.getValue()))
.limit(num)
.collect(Collectors.toList());
List<Long> userIdList = topUserPairList.stream().map(userLongPair -> userLongPair.getKey().getId()).collect(Collectors.toList());
QueryWrapper<User> userQueryWrapper = new QueryWrapper<>();
userQueryWrapper.in("id", userIdList);
Map<Long, List<User>> userIdUserListMap = this.list(userQueryWrapper)
.stream()
.map(this::getSafetyUser)
.collect(Collectors.groupingBy(User::getId));
List<User> finalUserList = new ArrayList<>();
for (Long userId : userIdList) {
finalUserList.add(userIdUserListMap.get(userId).get(0));
}
return finalUserList;
}
这种方式在数据量大时会存在内存占用高和计算时间长的问题。
使用优先队列优化:
为了解决上述问题,使用优先队列进行优化,只需要维护num个数据即可。优化后的代码如下:
public List<User> matchUsersByPriorityQueue(long num, User loginUser) {
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
queryWrapper.select("id", "tags");
queryWrapper.isNotNull("tags");
// 获取所有用户列表
List<User> userList = this.list(queryWrapper);
// 获取登录用户的标签
String tags = loginUser.getTags();
Gson gson = new Gson();
List<String> tagList = gson.fromJson(tags, new TypeToken<List<String>>() {
}.getType());
// 创建一个优先队列,按照距离进行排序 队列始终保持最小距离的用户,每次删除编辑距离值最大的那个
PriorityQueue<Pair<User, Long>> priorityQueue = new PriorityQueue<>((a, b) -> (int) (b.getValue() - a.getValue()));
// 遍历所有用户,计算距离并加入优先队列
for (User user : userList) {
String userTags = user.getTags();
if (StringUtils.isBlank(userTags) || user.getId().equals(loginUser.getId())) {
continue;
}
List<String> userTagList = gson.fromJson(userTags, new TypeToken<List<String>>() {
}.getType());
int distance = AlgorithmUtils.minDistance(tagList, userTagList);
priorityQueue.offer(new Pair<>(user, (long) distance));
// 保持优先队列的大小不超过 num
if (priorityQueue.size() > num) {
priorityQueue.poll();
}
}
//获取id列表
List<Long> matchUserIds = priorityQueue.stream()
.map(userLongPair -> userLongPair.getKey().getId())
.collect(Collectors.toList());
QueryWrapper<User> userQueryWrapper = new QueryWrapper<>();
userQueryWrapper.in("id", matchUserIds);
List<User> users = this.list(userQueryWrapper)
.stream()
.map(this::getSafetyUser)
.collect(Collectors.toList());
return users;
}
通过使用优先队列,只保留分数最高的用户,避免了存储所有用户数据导致的内存占用过高问题,同时也减少了排序的计算量。
将两种方法进行测试比较
@Override
public List<User> matchUsers(long num, User loginUser) {
//先查一次数据库,防止数据库连接耗时。影响了下面的对比
this.getById(loginUser.getId());
long startTime1 = System.currentTimeMillis();
List<User> users1 = matchUsersByListSorted(num, loginUser);
long endTime1 = System.currentTimeMillis();
long executionTime1 = endTime1 - startTime1;
long startTime2 = System.currentTimeMillis();
List<User> users2 = matchUsersByPriorityQueue(num, loginUser);
long endTime2 = System.currentTimeMillis();
long executionTime2 = endTime2 - startTime2;
log.info("使用list排序耗时:{}ms,使用优先队列耗时:{}ms,差距:{}ms,优化比例:{}%",
executionTime1, executionTime2, executionTime1 - executionTime2,
(executionTime1 - executionTime2) * 100 / executionTime1);
return users2;
}
结果如下:
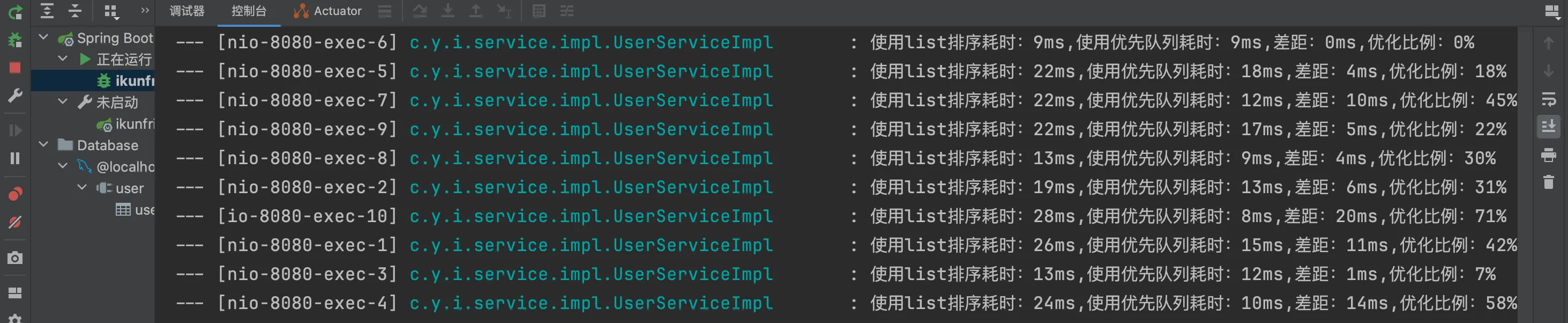
通过测试类进行测试:
@Test
void matchUsers() {
int num = 10;
User user = userService.getById(1001);
long costTime1 = 0;
long startTime1 = System.currentTimeMillis();
for (int i = 0; i < 100; i++) {
List<User> users1 = userService.matchUsersByListSorted(num, user);
}
long endTime1 = System.currentTimeMillis();
costTime1 = endTime1 - startTime1;
long startTime2 = System.currentTimeMillis();
for (int i = 0; i < 100; i++) {
List<User> users2 = userService.matchUsersByPriorityQueue(num, user);
}
long endTime2 = System.currentTimeMillis();
long costTime2 = endTime2 - startTime2;
log.info("100运算情况下:List排序耗时:{}ms,优先队列耗时:{}ms,相差:{}ms,优化比例:{}%", costTime1, costTime2, costTime1 - costTime2,
(costTime1 - costTime2) * 100 / costTime1);
}
结果如下:

从测试结果可以看出,使用优先队列的方法在性能上有明显的优势,能够大大减少计算时间和内存占用,提高伙伴匹配的效率。