IM顶层设计
整体架构图
集群推送
http是无状态的,每次请求进行三次握手,然后发送消息获取响应,因此HTTP可以随意的做负载均衡
但是WebSocket是有状态的,当建立了 TCP链接之后,就会一直复用那个通道进行通信。
我们之前在用户登录的时候,保存到<uid,channel>的映射关系,但是是保存到一台JVM的内存里的,如果有集群,多台JVM运行,那么这种方式就失效了
Redis存储channel(❌)
用Redis中心化来 存储<uid,channel>的映射关系,使用的时候,再反序列化为channel使用
问题:channel是本地的socket连接,没法进行存储和 ��反序列化 ,它是有状态的
精准投放消息
我们本地依然要去维护<uid,channel>的映射关系

比如现在A想要给C发送一条消息,那么 就有以下步骤:
- A通过Websocket的 Channel将消息发送到了IM后台服务。
- IM服务将消息持久化 ,然后 通过Router,想要转发消息给C
- Router去Redis中找到C的服务器IP地址,Router会和所有的Websocket建立一条TCP链接,然后发送到对应的IP地址
- WebSocket收到A发送的消息后 ,通过本地的
<uid,channel>的映射关系,然后找到C所在的Channel,调用channel,write将消息 发送给C
问题:
- 需要去频繁更新Redis维护用户和WebSocket的服务映射
- 连接数💥问题:websocket的瓶颈在于连接数,连接数满了,那么就会扩容WebSocket,使得可以支撑更多人同时在线,如果用户量非常大,那么就需要上千个WebSocket和 上千个Router
我们每个Router都会链接所有的WebSocket,总的连接数就是他们的乘积,1000*1000=1百万💥

这个问题也会出现在Dubbo中,如果Dubbo单实例集群达到1000以上,如何做?
分层路由思想:

我们在中间多加一层路由,就可以有效的减少非常多的连接数
- 消息发送开销:对于一个群聊,假如有1000个用户,那么就需要1000次推送,这个是必须的,但是我们的IM这边,通过Router进行转发,路由服务对每个用户都需要1000次的路由,每个用户都需要路由到每个WebSocket,需要把1条消息路由1000次,这部分是很大的开销
- 延迟叠加:即使使用多线程,也需要对所有的群成员进行消息的扇出(写扩散),会导致接收者接到的消息延迟叠加。
- 雪崩问题:如果WebSocket推送不及时,我们又是同步调用,那么WebSocket就会反向传导到Router服务 ,导致Router变慢 ,然后继续往回 传导到IM服务 ,导致全部变慢 ,导致所有的服务不可用,这个时候就需要MQ来做一个削峰填谷。
消息扇出:万人群聊,发一条消息,得在Router查一万次 这个用户在哪里,然后对一万个用户都进行一次消息的发送
集群广播
消息发送到IM服务后,IM服务会将消息写入消息队列,消息队列是一个广播消息,所有的WebSocket都去监听这个广播Topic,
所有的消息会推送到每一个WebSocket上,WebSocket拉取到消息后,它会来比对这个消息是否是自己需要的(会路由所有的WebSocket,WebSocket自己过滤)
对比之前的精准投递,如果一个群有一万个人,那么就会路由一万次,发送到这个WebSocket,再由WebSocket发送到具体用户

WebSocket消息过滤:

共享消息副本
在万人群聊中,大家收到的消息都是一样的,那么我们就可以共用一个消息体,在投递消息到MQ的时候,可以设置投递的消息为List<Long>的uids,而不是拆分多次投递
投递公式:
精准投递:u*3份消息,u=群聊在线人数,3=消息传输的链路,固定值
集群广播:u+n份消息,u=群聊在线人数,n=websocket的集群数,不固定,但是极小。
缺点 :只适合大群聊,小群聊或者单聊占比多,就会失去优势
消息过滤优化
我们消息是被发送到WebSocket的地方进行UID的过滤,这时候就会有大量与本websocket无关的消息拉取过来,中间的网络IO就会 浪费了。
集群广播的最大问题就在于很多不属于我们websocket的消息推送,也会被我们读取,然后在本地过滤,这里浪费了网络IO,浪费了本地反序列化的CPU
解决办法:
-
将推送的uids放到header里面,拉取消息的时候,先在MQ的过滤器过滤消息,节省不必要的反序列化
header长度有限,大群聊uid过多分批发送,或者群聊不过滤,考虑单聊场景
-
魔改RocketMQ,在broker里面过滤,节省 IO
百万直播间消息推送
问题背景:
- 在抖音直播场景下,一个热门直播间可能同时有100万人在线,大量礼物和互动消息需要即时推送给所有观众。
方案设计:
- 采用集群推送方式,将用户的 WebSocket 连接集中路由到固定的几百台服务器上,以减少扩散系数。
- 对于超过1万人的热门直播间,进行升级处理:
- 动态扩容 WebSocket 服务器集群至 50 台左右,并通过网关路由将用户连接重新分配到新集群。
- 对于这种热门直播间,可以省略升级过程,直接分配到固定集群。
- 消息推送采用广播方式,减少带宽开销:
- 将同一直播间的所有消息(如点赞、弹幕等)广播到集群内的 WebSocket 服务器,再由这些服务器转发给对应的用户。
- 对消息进行优先级隔离:
- 将高优先级消息(如大礼物、主播发言)和低优先级消息(如普通弹幕)分开推送,避免相互影响。
其他优化:
- 客户端和服务端都进行消息合并,减少实际推送量。
- 依赖网关路由服务来确定消息推送的目标(普通直播间 vs 热门直播间)。
消息时序性
消息的顺序性:
每条消息发送来,服务端收到的消息是并发的,那么就可能出现发送方和接收方顺序不一致的情况
解决办法:我们可以让客户端加上时间戳,展示的时候,再根据时间戳进行排序
微信的设计:单聊消息 MsgSeq 字段的作用及说明:该字段在发送消息时由用户自行指定,该值可以重复,非后台生成,非全局唯一。与群聊消息的 MsgSeq 字段不同,群聊消息的 MsgSeq 由后台生成,每个群都维护一个 MsgSeq,从1开始严格递增。单聊消息历史记录对同一个会话的消息先以时间戳排序,同秒内的消息再以 MsgSeq 排序。
参考上面的设计,我们可以给消息设置一个本地的自增id,发送消息的时候带上。排序整体以服务器的时间为准,相同秒内的排序以自增id为准。
在群聊场景下,每个成员的客户端时间不一样 ,没法 统一排序 ,只能用服务端时间排序。
服务端排序:对于单表来说,可以按照主键ID进行排序,也可以按照时间戳,但是时间戳也会有精度问题,到毫秒左右足够了。
消息的唯一性:
游标翻页的时候,需要保证顺序性和唯一性,如果单纯用时间戳,毫秒内的消息没办法区分和排序,得额外有其他字段排序,不如统一用有序的ID作为游标
综上:
单聊可以用客户端seq来保证多条消息的顺序
用消息ID可以满足顺序性和唯一性要求
消息ID设计
我们希望消息的ID具有唯一,有序的特点
唯一可以用分布式ID实现,有序如何保证?
全局递增
单表:主键保证了递增
但是消息大了,就必须要分库分表,采用分布式ID,但是分布式ID是趋势递增,而不是单调递增
严格单调递增会有严重的单点竞争,难以实现
会话级别递增
我们想要递增就是为了满足消息的顺序性,那么只要满足一个群组里面消息ID唯一且有序就足够了。
如何保证会话级别递增?分库分表以会话ID分表,相同会话必定在同一表中。但是这种方案很难进行扩容
所以还是采用分布式ID保证会话级别的单调递增
收信箱递增
会话级别递增适合读扩散场景,所有人都去拉取消息列表,去会话的消息表拉取
收信箱的递增适合写扩散场景,所有人都有自己的收信箱,维护自己的时间线。收信箱的单调递增和uid相关
消息可靠性ACK
发出去的消息要保证能够被对方收到,主要有两个场景
- 发送方发送消息到服务端,服务端入库成功返回ACK
- 服务端推送消息到接收方,接收方返回ACK
发送可靠性保证
发送消息不能用TCP的ACK来保证,因为请求到达服务端的时候,TCP的ACK已经确认了,但是我们的业务逻辑中也可能失败,因此只有业务返回的ACK才可以保证可靠性
我们使用HTTP发送消息,通过返回的表示,判断消息是否发送成功
推送可靠性保证
服务端消息入库后,推送给接收方,要保证接收方可以收到消息,推送给每个人的ACK都需要确认,然后修改这条消息的状态持久化道数据库。
重试机制:如果信箱没有收到ACK,说明消息没有到达接收方,那么就会进行重试,可以使用定时任务来完成,但是如果用户不在线,不可能一直去推送,所以我们的定时任务只会去拉取内存中的ACK队列进行推送,并且只推送在线消息。如果内存队列ACK满了,那么我们可以使用LRU算法,淘汰老的消息
离线推送:对于不在线的用户,在下一次连接上的时候,再推送消息。
如果用户很长时间没上线,没有ACK的消息过多,一次性推送所有消息,容易产生问题,可以分批推送
万人群聊中,1条消息要写1万人的收信箱,写扩散系数💥,每条消息都要写一份消息id到每个人的信箱
消息重复-幂等性
最终一致性 ,持久化,重试,幂等
在分布式场景下一般为了达到最终一致性,失败了我们也需要进行重试,重试就有幂等问题
发送幂等性设计
发送消息的时候,如果网络有问题,那么底层会帮我们重试,如何保证发送的幂等性,不重复发送?靠的是发送端生成一个唯一标识,后端根据这个唯一标识做幂等,但是我们后端只看1s内的去重,发送端也限制1s内不成功就放弃
接收幂等性设计
靠消息的ID来保证
会话级别的消息,判断会话id+消息id
推拉结合
推模式
服务端主动推送给前端,后台维护定时任务,定时推送未接收到ack的消息。
拉模式
短轮询和长轮询。前端主动询问后端是否有新消息。主要用在拉取历史消息列表
推拉结合
推主要是保证及时性。而拉主要是保证最终一致性
推模式(服务端主动推送)虽然能保证消息及时性,但需要处理推送失败的情况,服务端还需要启动定时任务确保接收方确认(ACK),整个方案比较复杂,对服务器也有较大消耗。
实际上推送失败概率并不高,如果客户端定期主动拉取消息,就可以达到最终一致性,无需服务端的复杂处理。
因此采用推拉结合的方式:
- 推模式主要用于保证消息及时性
- 拉模式主要用于保证消息最终一致性和可靠性
-
推送模式下,推送消息可以是无状态的,只是为了触发客户端拉取,实现很简单。
-
客户端拉取消息时,只需带上token即可,服务端查询未确认的消息并全部返回。
-
客户端接收到消息后可批量确认(ACK),服务端收到确认后将消息标记为已读。
-
为了优化查询性能,服务端可以建立"用户ID + 未确认"的联合索引。
-
通过推拉结合,可以实现无状态请求,减轻服务端压力,并提高客户端拉取效率。但依然没有解决大群聊下写扩散的问题。
多端同步-客户端游标
推拉结合的方案在多端同步的场景下会失效。因为在单端场景下,消息的状态只有一个ack(是否已读)标记。但在多端场景下,需要为每个端独立维护ack状态,变得复杂。
为了解决这个��问题,提出了一种新的方案:
- 服务端不再维护ack状态,而是由客户端维护自己的"游标"(已读到的最后一条消息的ID)
- 客户端在拉取消息时,需要带上自己的游标
- 服务端根据客户端的游标,查询出大于该游标的所有新消息返回
这种方案的关键是:
- 消息ID需要是全局递增的,这样服务端只需维护一个游标
- 如果消息ID是收信箱级别递增的,也可以实现类似效果,只是客户端需要维护每个会话的游标
这种基于客户端游标的方案可以很好地解决多端同步的问题,避免了服务端维护多端ack状态的复杂性。
由于我们的聊天室不需要保存历史消息,可以采用更简单的方案:登录每个端都加载最新的消息,后续通过拉取新消息的方式实现同步。
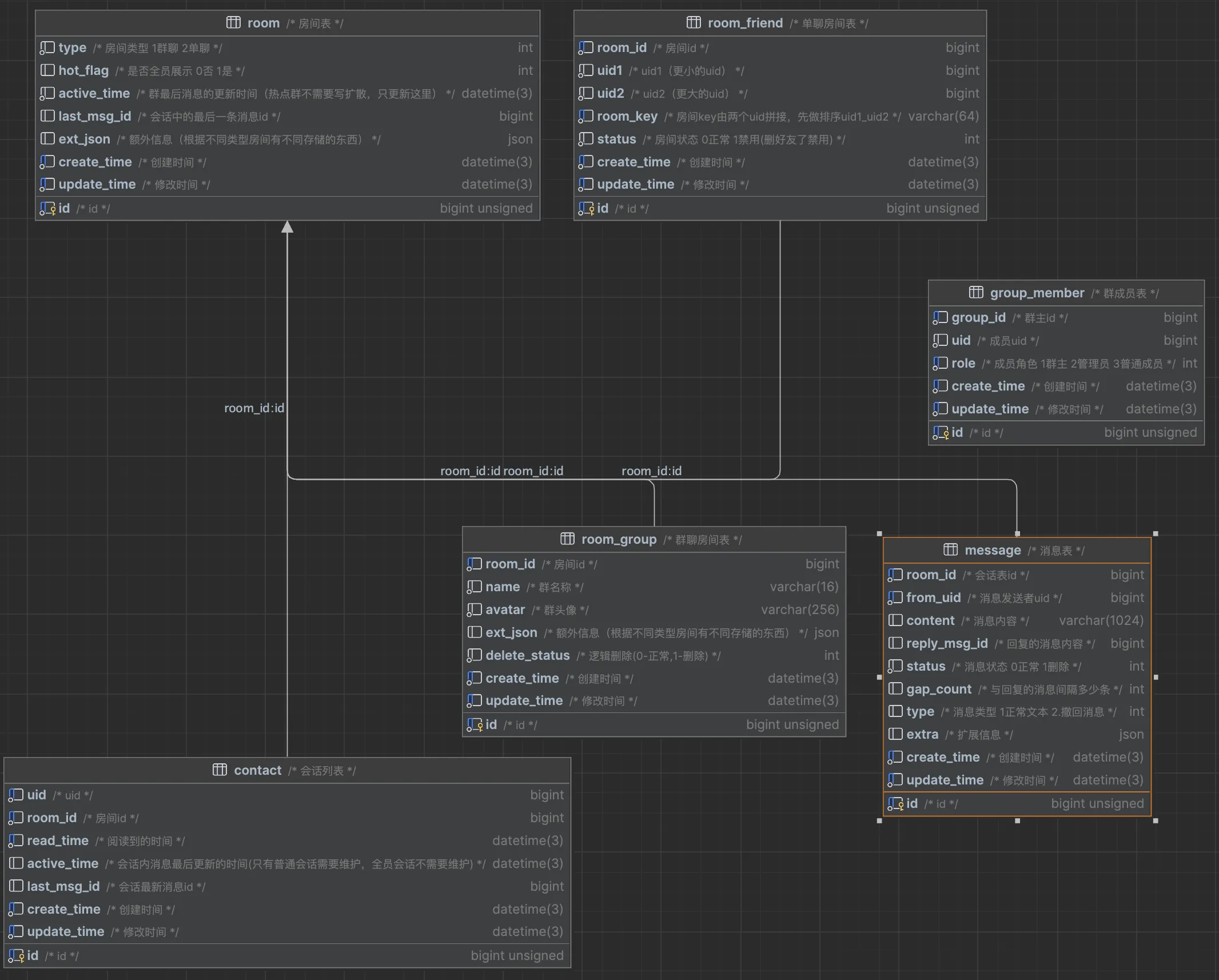
群聊设计
群聊设计,分为群聊和单聊(一对一)单聊也就是两个人在一个房间聊天,可以抽象出来

数据库设计:https://drawsql.app/teams/-328/diagrams/-6
消息已读未读
我们想要消息有以下信息显示:多�少人已读,未读、已读列表、未读列表
我们还是需要维护每个人对消息的ACK,每条消息都要投递到用户的收信箱,并且需要记录已读未读的状态,用做ACK统计
流程如下:
- 有人发了条消息,群消息入库,并插入到群成员A和B的收信箱,此时都是未读状态
- 推送服务通知A和B拉取新消息。
- A正好在线,拉取了新消息,拉到消息后,返回ACK。
- 推送服务标记A对新消息的ACK。
- ack的消息同时需要推送给消息的发送者,同步更新
- 发消息的人想看看消息的相关情况。数据库查询
收信箱写扩散💥
万人群聊,发送一条消息,就要写入到1万人的收信箱,每人发一条消息,就有1亿的消息量要存储
解决办法:用户收信箱不记录ACK,只记录阅读的最新时间线,这样只和群成员数有关,每个人一行阅读记录,然后在统计有多少人阅读的时候,只要去看这个人的阅读最新时间线是否>消息的发送时间
消息阅读推送
有人阅读消息后,消息阅读数+1,如何显示给用户?
最简单的办法,有人阅读就+1,然后推送给前端,但是这样频率太高了。可以采用服务端定时任务的方式。定时任务的间隔,就成为了合并的时间窗口。
实现的时候,我们只要去做最近一个频率的消息阅读量,不需要为每个消息都去统计已读未��读数量。通过前端的定时请求,让消息的已读数更新,避免了性能的无效浪费
左侧会话列表
会话列表排序 :左侧的会话列表要按照发送消息的最新时间来进行排序,并且是倒叙,最新时间的要放在上面
消息未读数:会话列表要可以显示未读的消息数,这个可以直接按照自己最新读取消息的时间去查询,但是如果很多年没上线,消息数实在太多了,这个时候,我们可以加个限制,最多显示99条未读数。也就是在SQL语句的最后加个limit 100
热点群聊-读写扩散
万人群聊,每条消息都需要写入用户的收信箱,也就是会话表的active_time字段,更新了这个字段,最新消息的会话才会排在前面。
这个更新时间要记,不扩散写到用户的收信箱,而是单独写到热点信箱,用户读取的时候,综合读取:自己的信箱+热点信箱,将两个合并在一起
消息多类型设计
消息支持多种格式,主要用两个字段来 解决:
- type:消息是什么类型
- extra:消息详情
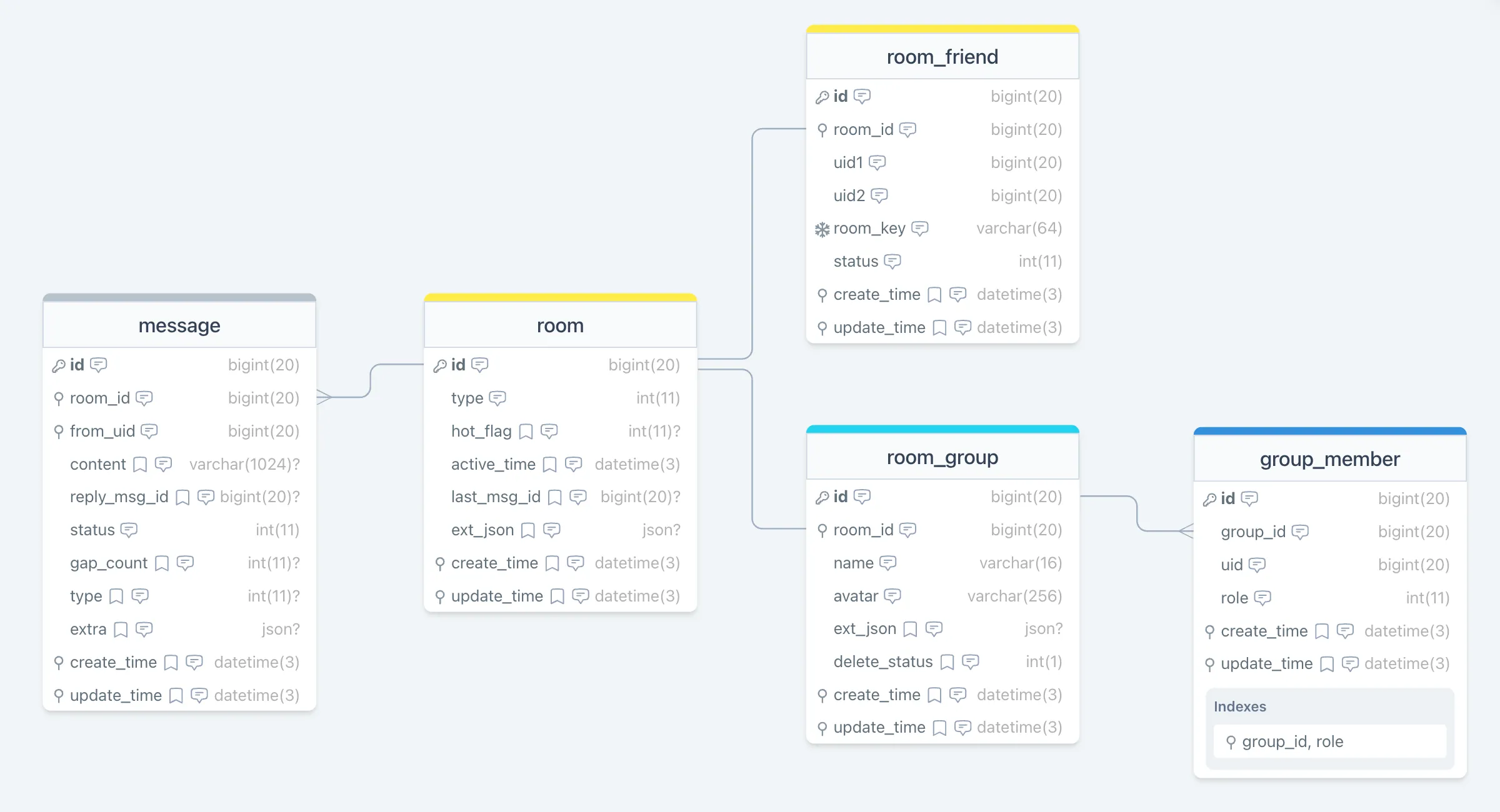
数据库设计
DROP TABLE IF EXISTS `room`;
CREATE TABLE `room` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'id',
`type` int(11) NOT NULL COMMENT '房间类型 1群聊 2单聊',
`hot_flag` int(11) DEFAULT '0' COMMENT '是否全员展示 0否 1是',
`active_time` datetime(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3) COMMENT '群最后消息的更新时间(热点群不需要写扩散,只更新这里)',
`last_msg_id` bigint(20) DEFAULT NULL COMMENT '会话中的最后一条消息id',
`ext_json` json DEFAULT NULL COMMENT '额外信息(根据不同类型房间有不同存储的东西)',
`create_time` datetime(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3) COMMENT '创建时间',
`update_time` datetime(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3) ON UPDATE CURRENT_TIMESTAMP(3) COMMENT '修改时间',
PRIMARY KEY (`id`) USING BTREE,
KEY `idx_create_time` (`create_time`) USING BTREE,
KEY `idx_update_time` (`update_time`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='房间表';
DROP TABLE IF EXISTS `room_friend`;
CREATE TABLE `room_friend` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'id',
`room_id` bigint(20) NOT NULL COMMENT '房间id',
`uid1` bigint(20) NOT NULL COMMENT 'uid1(更小的uid)',
`uid2` bigint(20) NOT NULL COMMENT 'uid2(更大的uid)',
`room_key` varchar(64) COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '房间key由两个uid拼接,先做排序uid1_uid2',
`status` int(11) NOT NULL COMMENT '房间状态 0正常 1禁用(删好友了禁用)',
`create_time` datetime(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3) COMMENT '创建时间',
`update_time` datetime(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3) ON UPDATE CURRENT_TIMESTAMP(3) COMMENT '修改时间',
PRIMARY KEY (`id`) USING BTREE,
UNIQUE KEY `room_key` (`room_key`) USING BTREE,
KEY `idx_room_id` (`room_id`) USING BTREE,
KEY `idx_create_time` (`create_time`) USING BTREE,
KEY `idx_update_time` (`update_time`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='单聊房间表';
DROP TABLE IF EXISTS `room_group`;
CREATE TABLE `room_group` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'id',
`room_id` bigint(20) NOT NULL COMMENT '房间id',
`name` varchar(16) COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '群名称',
`avatar` varchar(256) COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '群头像',
`ext_json` json DEFAULT NULL COMMENT '额外信息(根据不同类型房间有不同存储的东西)',
`delete_status` int(1) NOT NULL DEFAULT '0' COMMENT '逻辑删除(0-正常,1-删除)',
`create_time` datetime(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3) COMMENT '创建时间',
`update_time` datetime(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3) ON UPDATE CURRENT_TIMESTAMP(3) COMMENT '修改时间',
PRIMARY KEY (`id`) USING BTREE,
KEY `idx_room_id` (`room_id`) USING BTREE,
KEY `idx_create_time` (`create_time`) USING BTREE,
KEY `idx_update_time` (`update_time`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='群聊房间表';
DROP TABLE IF EXISTS `group_member`;
CREATE TABLE `group_member` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'id',
`group_id` bigint(20) NOT NULL COMMENT '群主id',
`uid` bigint(20) NOT NULL COMMENT '成员uid',
`role` int(11) NOT NULL COMMENT '成员角色 1群主 2管理员 3普通成员',
`create_time` datetime(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3) COMMENT '创建时间',
`update_time` datetime(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3) ON UPDATE CURRENT_TIMESTAMP(3) COMMENT '修改时间',
PRIMARY KEY (`id`) USING BTREE,
KEY `idx_group_id_role` (`group_id`,`role`) USING BTREE,
KEY `idx_create_time` (`create_time`) USING BTREE,
KEY `idx_update_time` (`update_time`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='群成员表';
DROP TABLE IF EXISTS `contact`;
CREATE TABLE `contact` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'id',
`uid` bigint(20) NOT NULL COMMENT 'uid',
`room_id` bigint(20) NOT NULL COMMENT '房间id',
`read_time` datetime(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3) COMMENT '阅读到的时间',
`active_time` datetime(3) DEFAULT NULL COMMENT '会话内消息最后更新的时间(只有普通会话需要维护,全员会话不需要维护)',
`last_msg_id` bigint(20) DEFAULT NULL COMMENT '会话最新消息id',
`create_time` datetime(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3) COMMENT '创建时间',
`update_time` datetime(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3) ON UPDATE CURRENT_TIMESTAMP(3) COMMENT '修改时间',
PRIMARY KEY (`id`) USING BTREE,
UNIQUE KEY `uniq_uid_room_id` (`uid`,`room_id`) USING BTREE,
KEY `idx_room_id_read_time` (`room_id`,`read_time`) USING BTREE,
KEY `idx_create_time` (`create_time`) USING BTREE,
KEY `idx_update_time` (`update_time`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='会话列表';
DROP TABLE IF EXISTS `message`;
CREATE TABLE `message` (
`id` bigint(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT 'id',
`room_id` bigint(20) NOT NULL COMMENT '会话表id',
`from_uid` bigint(20) NOT NULL COMMENT '消息发送者uid',
`content` varchar(1024) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '消息内容',
`reply_msg_id` bigint(20) NULL DEFAULT NULL COMMENT '回复的消息内容',
`status` int(11) NOT NULL COMMENT '消息状态 0正常 1删除',
`gap_count` int(11) NULL DEFAULT NULL COMMENT '与回复的消息间隔多少条',
`type` int(11) NULL DEFAULT 1 COMMENT '消息类型 1正常文本 2.撤回消息',
`extra` json DEFAULT NULL COMMENT '扩展信息',
`create_time` datetime(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3) COMMENT '创建时间',
`update_time` datetime(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3) ON UPDATE CURRENT_TIMESTAMP(3) COMMENT '修改时间',
PRIMARY KEY (`id`) USING BTREE,
INDEX `idx_room_id`(`room_id`) USING BTREE,
INDEX `idx_from_uid`(`from_uid`) USING BTREE,
INDEX `idx_create_time`(`create_time`) USING BTREE,
INDEX `idx_update_time`(`update_time`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_unicode_ci COMMENT = '消息表' ROW_FORMAT = Dynamic;
INSERT INTO `user` (`id`, `name`, `avatar`, `sex`, `open_id`, `last_opt_time`, `ip_info`, `item_id`, `status`, `create_time`, `update_time`) VALUES (1, '系统消息', 'http://mms1.baidu.com/it/u=1979830414,2984779047&fm=253&app=138&f=JPEG&fmt=auto&q=75?w=500&h=500', NULL, '0', '2023-07-01 11:58:24.605', NULL, NULL, 0, '2023-07-01 11:58:24.605', '2023-07-01 12:02:56.900');
insert INTO `room`(`id`,`type`,`hot_flag`) values (1,1,1);
insert INTO `room_group`(`id`,`room_id`,`name`,`avatar`) values (1,1,'抹茶全员群','https://mallchat.cn/assets/logo-e81cd252.jpeg');