STL容器
1.vector
1.简要描述:vector是容器,可以理解为C++中的数组/链表,访问可通过[]来完成
2.头文件:\#include< vector>
3.定义格式:vector<变量类型> 数组名称; 例如:vector< int> a;
4.常用函数:
push_back() // 尾部插入数组元素
pop_back() // 删除尾部数组元素
insert(a.begin()+i, num) // 将num插入第i+1个位置上,后面依次向后串位
erase(a.begin()+i) // 将第i+1个元素删除,后面依次向前串位
erase(a.begin()+i, a.begin()+j); // 删除区间[i, j-1]。区间从0开始
size() // 返回数组中元素个数
clear() // 清空数组元素,元素个数归为0
empty() // 判断数组是否为空,不空返回false,空返回true
resize() // 重新指定数组长度
begin()和end()怎么使用?
/*begin()和end()产生指向容器的第一个元素和最后一个元素的下一个位置的迭代器,常用于标记容器中元素的迭代范围。另外,容器还定义了rbegin()和rend(),返回指向容器最后一个元素和第一个元素的前一个位置的反向(reverse)迭代器。Begin()和end()与索引下标不同,所以不是int类型。*/
//输出指定的整型顺序容器的元素
Template<class T>
void printContainer(const char *msg, const T& s) {
cout<<msg<<”:”;
copy(s.begin(), s.end(), ostream_iterator<int>(cout, “ “));
// ostream_iterator是用于输出的迭代器类,ostream_iterator<int>(cout, “ “) 绑定标准输出装置。“ ”代表每个字符以空格间隔
cout<<endl;
}
2.pair
1.简要描述:pair是将两个数据组合成一组数据,pair的实现其实是一个结构体,既然是将两个数据组合成一个数据,那么里面自然就有两个数据了,我们将其称之为成员变量,分别为first和second。
2.头文件:#include<utility>
3.定义格式:pair<p1,p2>name;
3.string
1.简要描述:string是字符串模板类,可理解字符数组。访问元素可通过[]完成,对象赋值可使用=
2.头文件:#include< string>
3.定义格式:string a;
4.常用函数:
assign(s1, b, c) // 使用s1对象对a赋值,从b开始到c结束(0开始,左闭右闭)。缺省bc全部赋值
length()/size() // 返回字符串的长度
append(s1, b, c) //添加至字符串末尾,从b开始到c结束(0开始,左闭右闭)。缺省bc全部赋值
<、<=、==、!=、>=、> 对象间比较大小。
compare(b, c, s1,m,n) // 比较两string对象大小,bc是自己索引,mn是s1索引。均可缺省。返回值三种:大于0,等于0,小于0
swap(s2) // 本对象与s2对象交换内容
substr(m, n) // 取子串,从m索引开始,长度为n。n可缺省
replace(b,c,s1,m,n) //字符串替换,用s1的[m,n]替换原对象的[b,c]。c-b=n-m。
erase(b, c) // 删除子串[b,c],后面依次向前补。c可缺省,删除到底
insert(b, s1) // 在索引b处插入对象s1,原对象依次向后串
find(b, c) // 返回值是int型,返回出现指定字符的下标。b是内容,c是开始位置(可缺省)。常通过for循环使用,终止条件是:(position=s.find(b,c))!=string::npos
4.queue队列
1.简要描述:queue完成的功能是队列,即先进先出
2.头文件:#include< queue>
3.定义格式:queue<变量类型> 队列名称; // 例如:queue< int> a;
4.常用函数:
front() // 获取队首元素,但并不删除
back() // 获取队尾元素,但并不删除
pop() // 删除队首元素,无返回值
push() // 向队列中加入元素,放置队列末尾
empty() // 判断队列是否为空,不空返回false,空返回true
size() // 返回队列中元素的个数
5.priority_queue优先队列
1.简要描述:在优先队列中,优先级高的元素先出队列,并非按照先进先出的要求,类似一个堆(heap)
2.头文件:#include <queue>
3.定义格式:priority_queue <int> ans
4.常用函数:
empty( ) //判断一个队列是否为空
pop( ) //删除队顶元素
push( ) //加入一个元素
size( ) //返回优先队列中拥有的元素个数
top( ) //返回优先队列的队顶元素,top()返回的是最大值而不是最小值
6.stack栈
1.简要描述:stack完成的功能是栈,即队列中后进先出
2.头文件:#include< stack>
3.定义格式:stack<变量类型> 栈名称; // 例如:stack< int> a;
4.常用函数:
push() // 将变量压入栈顶
pop() // 栈顶出栈,无返回值
top() // 返回栈顶元素,不出栈
empty() // 判断栈是否为空,不空返回false,空返回true
size() // 返回栈中元素的个数
swap(s,s1) // 交换两个栈(s,s1)中全部元素
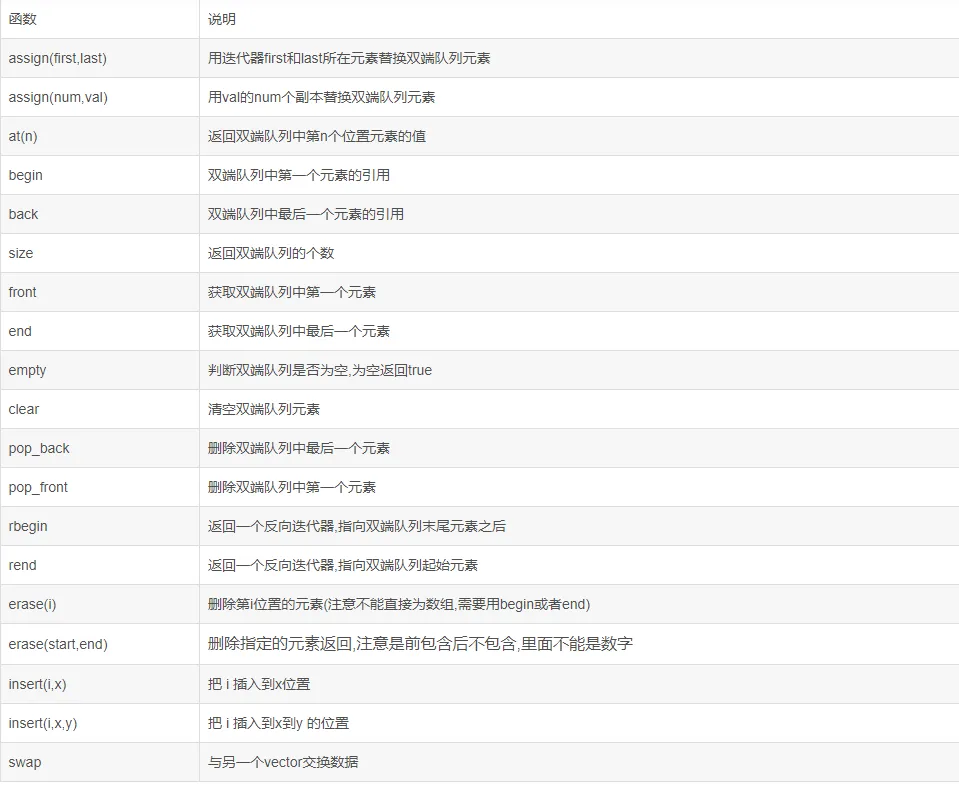
7.deque双端队列
1.介绍:deque是双端队列,不论在尾部或头部插入元素,都十分迅速。而在中间插入元素则会比较费时,因为必须移动中间其他的元素。双端队列是一种随机访问的数据类型,提供了在序列两端快速插入和删除操作的功能,它可以在需要的时候改变自身大小,完成了标准的C++数据结构中队列的所有功能。它不像vector一样把所有对象保存在一个连续的内存块,而是多个连续的内存块。并且在一个映射结构中保存对这些块以及顺序的跟踪。
2.头文件:#include<deque>
3.定义格式:deque<int> a;
4.常用函数:
8.set,map,multiset,multimap
map
1.简要描述:map用于键值和数值对应。按照键值有序排列(从小到大)。相当于一维数组,键值为索引,数值为数组值(赋值时可以这么理解使用[],遍历时不使用[])可以理解为集合中有多个相同有序元素
2.头文件:#include< map>
3.定义格式:map<数据类型1,数据类型2> 变量名 // 例如:map<int, int> a;
4.常用函数:
insert() // 插入元素,成对儿插入。插入的方式有两种:{0,1},pair<int, int>(0,1)。后者更常用
erase() // 删除元素,删除有两种类型:迭代器删除或键值删除。键值删除,返回值是删除的个数。例如:num = s.erase(1)——删除键值为1的元素,并返回个数给num。迭代器删除,返回值是下一个位置的迭代器。例如:iter = s.erase(s.begin())。Iter指向第二个元素的迭代器
find() //查找给定主键的位置,返回的是迭代器。常用的判断语句时:s.find(0) != s,end()
clear() // 清空所有元素
count() //返回值为int型,返回目标主键的个数。没找到就是0了
empty() // 返回数组是否为空,不空返回false,空返回true
size() // 返回有效元素的个数
iter->first/iter->second // iter代表迭代器,first访问键值,second访问数值
对于map/set,unorderedmap/unorderedset迭代器定义方式为如下:容器类名::iterator 迭代器名;
例如:
unordered_set< int>::iterator a;
set< int>::iterator a;
unordered_map<int, string>::iterator a;
map<int, string>::iterator a;
9.unordered_set, unordered_multiset, unordered_multimap, 哈希表
1.简要描述:unordered_set相当于一个集合,集合的组织无序。数量唯一,只是用来判断是不是存在。
2.头文件:#include<unordered_set>
3.定义格式:unordered_set< 数据类型> 变量名; //例如:unordered_set< int> a;
4.常用函数:
find() // 查找目标数值,找到返回迭代器。常使用的�模板是s,find(a) != s.end()
count() // 返回指定值出现的次数,返回值为int型
empty() // 判断是否为空,不空返回false, 空返回true
size() // 返回数组大小
insert() // 插入元素,参数即插入的元素值
emplace() // 插入元素
erase() // 删除操作,两种方式:指定数值或者是迭代器。删除指定数值,返回值是0/1,代表是否删除成功。删除迭代器,返回值是下一个位置的迭代器。失败返回s.end()。
unordered与vector转换
unordered_set<int> set(vec.begin(), vec.end());//将vector转换为unordered_set
unordered_map
1.简要描述:unordered_map用于键值和数值的无序唯一排列,用于有二维要求的问题。也相当于一维数组,键值为索引,数值为数组值(赋值时可以这么理解使用[],遍历时不使用[])可以理解为集合中有多个相同无序元素。
2.头文件:#include<unordered_map>
3.定义格式:unordered_map<数据类型1,数据类型2> 变量名 // 例如:unordered_map<int, int> a;
4.常用函数:
begin()/end() // 迭代器,不是int型
size() // 返回有效元素的个数
empty() // 返回数组是否为空,不空返回false,空返回true
insert() // 插入元素,成对儿插入。插入的方式有两种:{0,1},pair<int, int>(0,1)。后者更常用
erase() // 删除元素,删除有两种类型:迭代器删除或键值删除。键值删除,返回值是删除的个数。例如:num = s.erase(1)——删除键值为1的元素,并返回个数给num。迭代器删除,返回值是下一个位置的迭代器。例如:iter = s.erase(s.begin())。Iter指向第二个元素的迭代器
clear() // 清空所有元素
find() //查找给定主键的位置,返回的是迭代器。常用的判断语句时:s.find(0) != s,end()
count() //返回值为int型,返回目标主键的个数。没找到就是0了
10.bitset压位
STL中一些比较常用的通用算法:
sort(a.begin(), a.end(), cmp)
头文件:#include< algorithm>
描述:功能是排序,前两个参数是迭代器,指定排序的范围。第三个是排序方式,缺省的话默认从小到达。自定义的话,返回值类型是staic bool cmp(int a, int b) {}
reverse(a.begin(), a,end())
头文件:#include< algorithm>
描述:功能是翻转,参数是两个迭代器。指定翻转范围
accumulate(起始地址,末尾地址+1,初始值);
头文件 algorithm
初始值就是数组相加之后加上的值
描述:功能是计算数组元素之和
min_element 和 max_element
头文件:#include<algorithm>
作用:返回容器中最小值和最大值的指针。max_element(first,end,cmp);其中cmp为可选择参数!
获取值需要在前面加上*,如*min_element(num,num+6)